by Hassaan Mazhar, Last updated: July 16, 2026

Your team needs to protect sensitive data. Legal is nervous, compliance is strict, and regulators keep tightening the screws. So you redact aggressively, just to be safe. Then months later, you discover the fallout. Analysts cannot use the data. Outside counsel pushes back. Opposing parties claim spoliation. Internal stakeholders lose trust in the process.
This is the core tension. You have to remove sensitive information, but you also have to preserve data value, meaning, and defensibility. Data redaction accuracy is where those pressures collide.
Data redaction accuracy as a daily business problem
For many organizations, redaction is not a rare event. It is part of everyday workflows:
- Responding to discovery and investigations
- Sharing recordings with external regulators or partners
- Releasing reports, records, and videos to the public
- Preparing evidence for litigation or audits
In each case, poor data redaction accuracy shows up quickly.
- Over redaction strips out context, weakens your position, and limits downstream analysis
- Under redaction exposes PII or PHI and triggers regulatory and legal exposure
- Inconsistent manual redaction creates gaps that opposing counsel will exploit
You are not just trying to hide data. You are trying to create a version of truth that is both compliant and usable. That is a data redaction accuracy problem, not a cosmetics problem.
Why data redaction accuracy is difficult in real operations
On paper, redaction sounds simple. Find sensitive information, mask it, and move on. In reality, operational constraints work against data redaction accuracy.
- High volume: Thousands of documents, hours of video, and large email collections
- Multiple formats: PDFs, Office files, chat logs, audio, and video
- Different rules: Varying legal standards across jurisdictions and use cases
- Limited time: Short response windows for subpoenas, FOIA, and regulator requests
Under pressure, teams often make tradeoffs that erode data redaction accuracy. They rely on quick manual passes, generic search terms, or basic tools that do not understand context. The result is a redaction workflow that technically removes information but leaves behind operational and legal risk.
Operational risks of poor data redaction accuracy
Data redaction accuracy is both a compliance and an operational issue. When it fails, the impact is broad.
Lost data value from over redaction
Over redaction is a defensive reflex. Teams black out entire sections, pages, or tracks to avoid missing anything. This protects in the short term but damages the long term value of your data.
- Analysts cannot identify patterns and behaviors
- Investigations lose important context and sequence
- Business stakeholders receive unusable outputs
Over time, this creates an expensive archive of neutered content. It is technically safe but practically useless. Data redaction accuracy requires precision, not blanket coverage.
Legal and regulatory risk from under redaction
On the other side, under redaction leaves sensitive data exposed.
- PII redaction accuracy is inconsistent, so some identifiers remain visible
- Audio or video redactions miss spoken names, locations, and account numbers
- Contextual clues reveal more than the masked fields suggest
This creates direct exposure under regulations like GDPR, CCPA, HIPAA, and sector specific rules. It also undermines your credibility with regulators and courts. When redaction software accuracy is low, the risks compound with every new matter.
Inconsistent workflows and defensibility gaps
Manual redaction processes often rely on individual judgment. One reviewer redacts aggressively. Another takes a lighter approach. A third relies mostly on keyword search.
When you later need to explain your process, these inconsistencies become a problem.
- Opposing parties challenge why some similar data was redacted and some was not
- Regulators question controls and governance
- Internal audit cannot verify that policies were applied consistently
Data redaction accuracy is not just about what is hidden. It is about whether you can explain and defend your decisions. That requires consistent, auditable workflows.
Common causes of inaccurate or inconsistent redaction
To improve data redaction accuracy, you have to address the root causes. Most organizations face a mix of these issues.
Manual, search based, and rules only approaches
Traditional approaches lean on manual effort and simple rules.
- Manual review of each page, frame, or transcript
- Keyword search for obvious identifiers
- Pattern based redaction for email, SSN, phone numbers, or account numbers
These methods are necessary, but not sufficient on their own. They miss context, implied identifiers, and variations in natural language. They also tend to slow down as volumes increase, which pushes reviewers to cut corners.
No unified approach across formats
Many teams use one process for documents and another for audiovisual content. For example:
- PDFs redacted in a separate tool with static rules
- Videos edited in a media tool with no metadata or transcript awareness
- Audio handled through manual listening and note taking
The result is uneven data redaction accuracy. Some formats receive precise redaction. Others receive broad, imprecise masking. That inconsistency creates risk and confusion.
Limited visibility into context
Accurate redaction depends on context. A phone number in one document might be harmless. The same number in another context is highly sensitive. Traditional tools rarely understand this.
Without context aware redaction, reviewers face a difficult choice.
- Redact broadly and sacrifice data value
- Redact narrowly and risk missing sensitive elements
Data redaction accuracy demands more than pattern matching. It requires systems that understand entities, relationships, and intent.
Principles for high data redaction accuracy without data loss
To implement redaction without affecting data accuracy, you need a set of guiding principles. These principles help align technology, process, and people.
1. Use context aware detection as the foundation
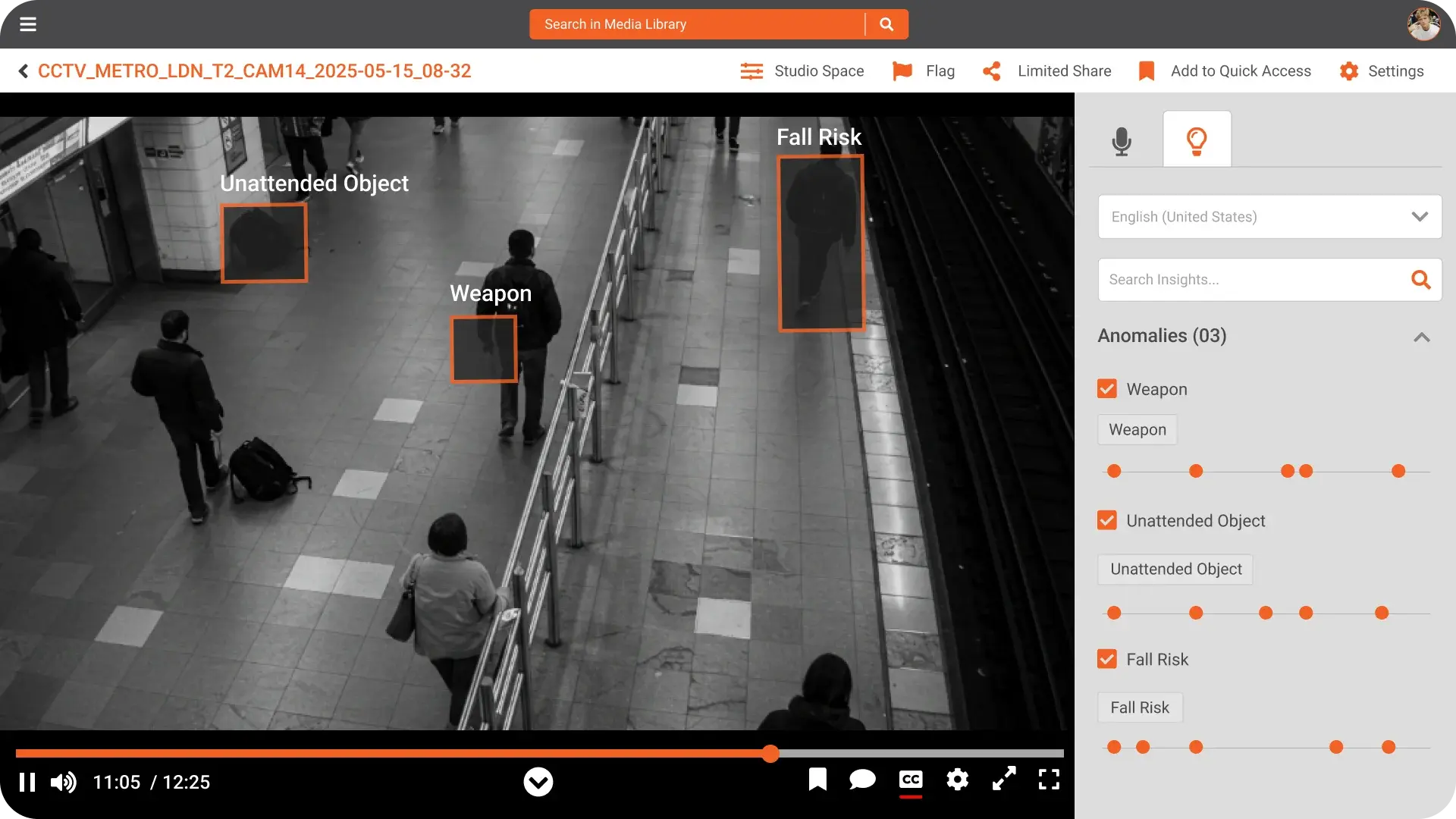
Context aware redaction is key to improving PII redaction accuracy and avoiding over redaction. Instead of looking only for patterns, systems should identify and classify entities in context.
- Detect names, addresses, and organizations in full sentences
- Understand roles like patient, employee, or customer
- Recognize sensitive combinations, not just individual fields
This context awareness drives higher data redaction accuracy because the system can distinguish between generic text and sensitive content that affects privacy or confidentiality.
2. Apply precision based masking instead of blanket blackouts
Redaction without data loss requires precise masking. Instead of covering entire pages or large segments, focus on:
- Masking only the sensitive tokens or segments
- Preserving surrounding text, timestamps, and events
- Maintaining chain of events in video and audio recordings
High data redaction accuracy means stakeholders can still reconstruct what happened, why it happened, and in what order, even though identifiers are hidden.
3. Maintain multi format consistency
Data redaction accuracy should not vary by file type. Your approach needs to cover:
- Documents and PDFs
- Spreadsheets and structured reports
- Emails, chats, and collaboration platforms
- Audio and video recordings
Automated redaction accuracy improves when the same detection logic and policies apply across formats. This avoids the common pattern where documents receive proper PII redaction accuracy but audiovisual content lags behind.
4. Keep humans in the loop for validation
AI powered redaction raises data redaction accuracy, but it does not remove the need for human judgment. Instead, it changes how reviewers work.
- AI handles initial detection and suggested redactions
- Reviewers validate, adjust, and approve with full control
- Feedback loops improve automated redaction accuracy over time
This human in the loop model balances speed, accuracy, and defensibility. You can point to both technology controls and expert oversight when challenged.
5. Build auditability into the process
Defensible redaction requires clear records. Your workflows should capture:
- What was detected and redacted
- Who reviewed and approved each change
- What rules or policies were applied
- Version history and change tracking
This level of auditability supports data redaction accuracy in two ways. It helps you improve processes over time, and it gives you evidence if your redaction decisions come under scrutiny.
How AI powered redaction improves data redaction accuracy
Traditional tools still play a role, but they do not fully meet current demands. AI powered redaction helps close the gap on several fronts.
Context aware detection at scale
AI models can analyze text, audio, and video content in context. This supports more accurate redaction across large volumes.
- Natural language understanding identifies entities and relationships
- Speech recognition converts audio to text for searchable redaction
- Computer vision detects visual identifiers in video frames
The result is higher data redaction accuracy and more consistent PII redaction accuracy across formats.
Improved redaction software accuracy over time
AI powered systems can learn from reviewer feedback. When reviewers correct or confirm suggested redactions, the system refines its models.
- Accuracy improves with each project and dataset
- Organization specific patterns and terms are captured
- Automated redaction accuracy becomes tailored to your environment
This adaptive capability is difficult to achieve with static rules or manual only approaches.
Better balance between protection and usability
AI powered redaction enables more nuanced decisions. Instead of choosing between all or nothing, you can configure rules based on:
- Regulatory requirements by region or practice area
- Use case, such as internal analytics versus public disclosure
- Risk profiles for specific data types
Targeted masking improves data redaction accuracy by aligning privacy protection with operational needs. You protect what you must and preserve what you can.
Example solution: preserving data accuracy with contextual AI
Some enterprise solutions, such as VIDIZMO REDACTOR, are built with data redaction accuracy at the center. While each platform differs, the core elements that matter are consistent.
- Contextual AI that combines speech recognition, natural language processing, and computer vision
- Configurable detection for PII, PHI, and other sensitive data types
- Frame accurate audio and video redaction with transcript alignment
- Reviewer dashboards that show all suggested redactions for validation
- Comprehensive audit trails for defensibility and internal review
These capabilities support accurate redaction without data loss across large, mixed format datasets. They improve redaction software accuracy while still giving legal and compliance teams final control.
For organizations that manage significant volumes of sensitive multimedia content, this type of contextual AI engine is often what lifts data redaction accuracy from manual best effort to repeatable process.
Practical steps to implement accurate redaction in your organization
Improving data redaction accuracy does not have to be an all at once transformation. You can move in structured steps.
1. Map current redaction workflows and pain points
Start by documenting how redaction really happens today.
- Where requests originate and how they are triaged
- Which teams handle which formats
- What tools and rules each group relies on
- Where errors, delays, or disputes are common
This gives you a baseline view of both compliance risk and operational inefficiency linked to low data redaction accuracy.
2. Define accuracy requirements by use case
Different use cases require different levels of data redaction accuracy.
-
- Public disclosures may require strict PII redaction accuracy and aggressive masking
- Internal analytics may allow for pseudonymization rather than full redaction
- Regulatory submissions often demand very clear, consistent rules
Clarify what accurate redaction means for each scenario. Then translate that into detection rules, reviewer checklists, and quality thresholds.
3. Pilot AI powered redaction on a real dataset
Next, test an AI powered redaction engine on a controlled but realistic dataset. Focus on:
- How well it detects sensitive entities in context
- Its automated redaction accuracy across text, audio, and video
- How easy it is for reviewers to validate and adjust suggestions
- How audit logs support compliance and defensibility
Measure data redaction accuracy before and after, not only by error rate but also by the usability of the redacted output.
4. Standardize policies and templates
Once you have validated an approach, codify it.
- Create standard redaction policies for each major use case
- Define sensitive data categories and examples
- Document reviewer workflows and escalation paths
- Establish quality checks and sampling procedures
These standards help maintain data redaction accuracy as volumes and teams scale.
5. Train reviewers on context, not just tools
Even with strong AI support, human reviewers remain central. Training should cover:
- How to interpret AI suggestions and confidence scores
- Where context aware redaction is critical to avoid over or under redaction
- How their corrections feed back into the system
- How to document decisions that may later need to be defended
This combination of technology, training, and governance is what ultimately improves data redaction accuracy at scale.

People Also Ask
You can measure data redaction accuracy using standard metrics such as precision and recall. Precision shows how many redactions were correct versus unnecessary. Recall shows how many sensitive items were correctly redacted versus missed. In practice, organizations often combine these with manual sampling of redacted outputs, review of edge cases, and tracking of incidents such as missed PII disclosures.
To avoid over redaction, you need context aware redaction and clear policies. Use AI powered tools to identify specific entities in context, then apply precision based masking rather than blanket blackouts. Define exactly which data elements must be removed for each use case, and train reviewers to preserve non sensitive context that supports analysis and defensibility.
AI improves PII redaction accuracy by analyzing language, audio, and visuals together rather than relying on simple pattern matching. It can recognize names, addresses, financial identifiers, and other entities even when they appear in varied forms. AI also helps connect related pieces of information that, in combination, reveal identity, which is difficult to manage with rules alone.
Automated redaction accuracy can approach or exceed human reviewers in many high volume, repetitive tasks, especially for structured PII. The best results come from a human in the loop model where AI handles initial detection and humans validate. Over time, as AI models learn from reviewer feedback, overall data redaction accuracy usually increases and becomes more consistent than purely manual work.
To ensure redaction software accuracy for audio and video, look for solutions that combine speech to text, natural language processing, and frame level video analysis. The system should align transcripts with audio and video timelines so that masking appears exactly where sensitive data is spoken or shown. Consistent testing with real samples and regular quality checks are also essential.
No. When implemented correctly, higher data redaction accuracy usually results in more usable data. Precise masking protects what must be hidden while preserving non sensitive context, structure, and sequence. Over redaction, not accuracy, is what often destroys data value. Context aware and precision based approaches help maintain both privacy and utility.
In mixed content sets, context aware redaction uses AI models to analyze each modality. Text is processed with natural language techniques, audio is transcribed and analyzed as text, and video is scanned for visual identifiers. The system then applies unified rules across all formats. This multi modal analysis supports consistent data redaction accuracy across documents, emails, audio, and video.
Strong governance controls include documented policies, clear approval workflows, audit logs, and periodic quality reviews. Your redaction solution should capture who made each decision, what was redacted, and why. Regular sampling of completed work, training refreshers, and alignment with legal and compliance teams all contribute to defensible data redaction accuracy.
When evaluating tools, test them on your real data, not only on vendor demos. Measure detection performance for your specific PII and PHI types, review automated redaction accuracy for both documents and media, and assess how easy it is for reviewers to validate and adjust suggestions. Also review audit capabilities and integration with your existing content and case management systems.
About the Author
Jump to

Key Features Retailer Should Look for in CCTV Video Redaction Software
.webp)
Best Redaction Software for Sensitive Data in 2026

No Comments Yet
Let us know what you think