by Umair Ahmad, Last updated: March 18, 2026

Organizations handling sensitive data face a critical question: should you redact it or mask it? Both methods protect personally identifiable information (PII), but they work in fundamentally different ways and choosing the wrong one can create compliance gaps or render data unusable.
Data redaction vs data masking isn't an either-or decision. Each method serves a distinct purpose, applies to different data types, and fits different stages of the data lifecycle. This guide breaks down exactly how they differ, when to use each, and how modern AI tools are changing the redaction equation for video, audio, and documents.
What Is Data Redaction?
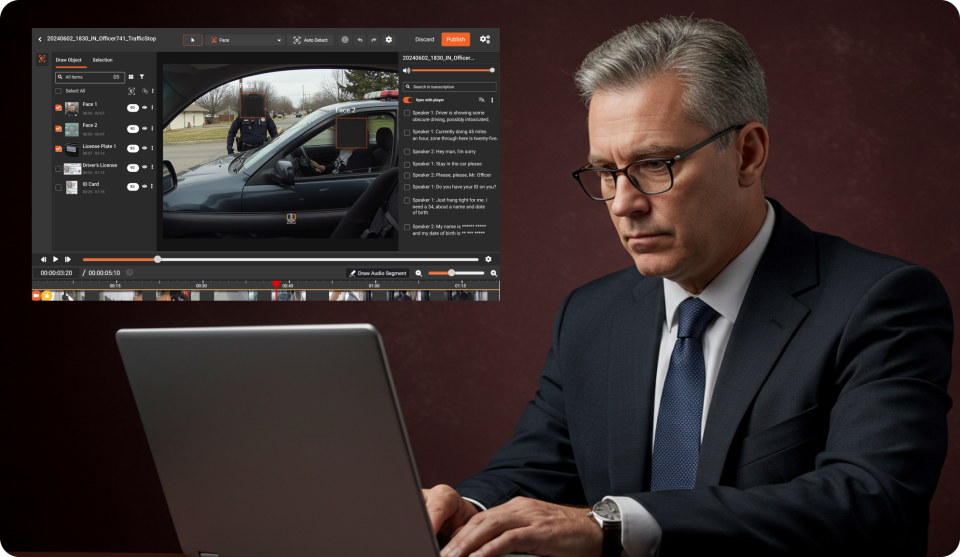
Data redaction permanently removes or obscures sensitive information from files so it can never be recovered. Once you redact a Social Security number from a PDF, black out a face in a video, or bleep a name from an audio recording, that data is gone for good.
Redaction applies across formats:
- Documents and PDFs: Blacking out text, names, addresses, account numbers
- Video: Obscuring faces, license plates, tattoos, screen content
- Audio: Bleeping or silencing spoken PII like names, dates of birth, and medical details
- Images: Covering identifiers in scanned documents, screenshots, or photographs
Organizations use redaction when sharing files externally: responding to FOIA requests, publishing court records, releasing body camera footage, or distributing medical records. The goal is always the same, make the sensitive information permanently inaccessible while keeping the rest of the content usable.
Key characteristic: Irreversible. The original data cannot be reconstructed from the redacted version.
What Is Data Masking?
Data masking replaces sensitive data values with realistic but fictitious alternatives. A customer's real name becomes "Jane Smith," a credit card number turns into "4111-XXXX-XXXX-1234," and an email address becomes "user@example.com." The masked data looks and behaves like real data, but it doesn't map to actual individuals.
There are three common types of data masking:
- Static data masking - creates a permanently masked copy of a database or dataset. Used for development and testing environments.
- Dynamic data masking - masks data in real time as users query it, based on their access level. The original data stays intact in the database.
- On-the-fly masking - masks data during transfer between systems, such as when moving production data to a staging environment.
Organizations use data masking when they need to preserve the structure and statistical properties of data for internal use, software testing, analytics, training, or third-party sharing where individual identities don't matter.
Key characteristic: Reversible (in most implementations). The original data still exists and can be accessed by authorized users.
Data Redaction vs Data Masking: Side-by-Side Comparison
.jpg?width=800&height=438&name=image%20(20).jpg)
The fundamental distinction: redaction destroys data for security, while masking disguises data for usability.
When to Use Data Redaction vs Data Masking
Choosing the right method depends on three factors: who will see the data, whether the data needs to remain functional, and what regulations apply.
Use data redaction when:
- Responding to public records requests. FOIA, CPRA, and open records laws require agencies to release documents with exempt information removed -- not masked, but permanently redacted. A FOIA officer processing body camera footage needs faces, license plates, and spoken names redacted before release.
- Sharing documents with opposing counsel. During eDiscovery, privileged or protected information must be redacted from produced documents. Courts expect permanent removal, not reversible masking.
- Publishing content publicly. Court records, government reports, and compliance disclosures going on public websites need PII permanently removed.
- Processing multimedia evidence. Video, audio, and image files require visual and auditory redaction -- techniques that masking tools (built for databases) simply don't support.
Use data masking when:
- Building development and testing environments. QA teams need realistic data to test software, but they don't need real customer records. Static masking creates a safe copy.
- Running analytics on sensitive datasets. Researchers analyzing healthcare outcomes or financial trends need the data's statistical properties without individual identities.
- Sharing data with third-party vendors. When a partner needs access to your data structure but not the actual PII, dynamic masking limits what they see based on their access level.
- Meeting pseudonymization requirements. GDPR specifically recognizes pseudonymization (a form of masking) as a valid data protection measure for processing personal data.
Use both when:
Many organizations need both methods across different workflows. A healthcare system might mask patient records for its research team while redacting the same patients' information from video consultations shared with external auditors. A law enforcement agency might mask database records for training scenarios while redacting body camera footage for FOIA responses.
How AI Is Changing Data Redaction
Traditional redaction was manual: an analyst would review every page, every frame, every audio segment, and manually mark what to remove. For a single hour of body camera video, that could take 4 to 8 hours of analyst time.
AI-powered redaction tools have compressed that timeline dramatically. Here's how:
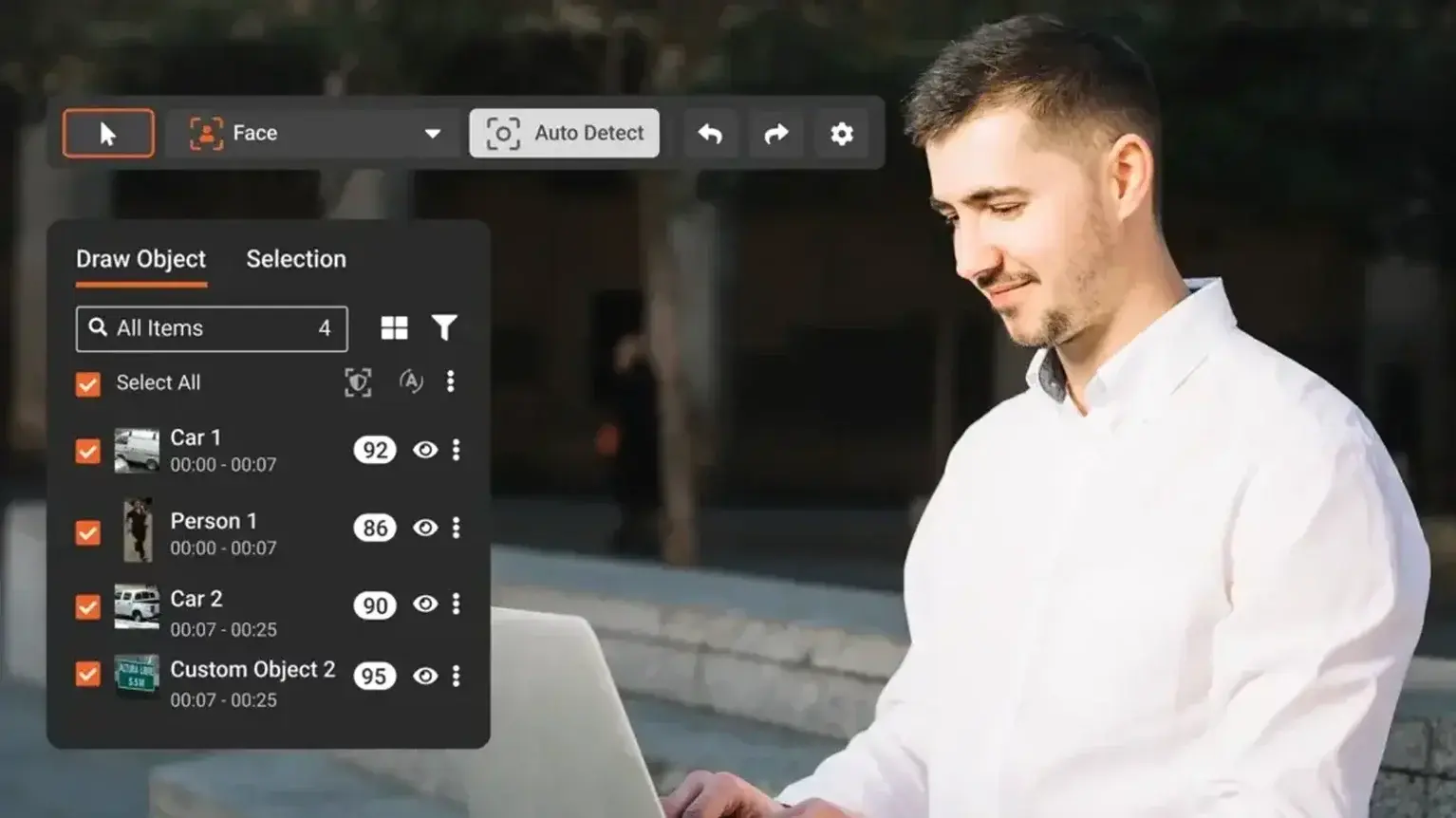
- Computer vision detects and tracks faces, license plates, tattoos, and other visual PII across video frames -- even when subjects move, turn, or are partially obscured.
- Natural language processing (NLP) identifies written PII in documents: names, addresses, Social Security numbers, medical record numbers, and 40+ other PII types.
- Speech-to-text with entity recognition transcribes audio and flags spoken PII categories -- dates of birth, phone numbers, case numbers, names -- across 82 supported languages.
- Configurable confidence thresholds let reviewers set how aggressively the AI flags potential PII, balancing thoroughness against false positives.
- Human-in-the-loop review combines AI speed with human judgment: the AI proposes redactions, and a reviewer approves, adjusts, or overrides before finalizing.
The result is that organizations processing hundreds or thousands of files can run bulk redaction workflows that would have been impossible with manual methods -- while maintaining accuracy through human oversight.
Industry-Specific Applications
Law enforcement and government
Agencies face growing volumes of FOIA requests for body camera footage, dashcam video, and incident reports. Redaction is legally required before release -- exemption codes (like FOIA Exemption 6 for personal privacy or Exemption 7(C) for law enforcement records) must be applied and documented. Masking doesn't apply here; the public expects permanent, irreversible removal.
Healthcare
HIPAA requires protecting Protected Health Information (PHI) in any shared records. For external disclosures -- insurance audits, legal proceedings, or patient record requests -- redaction removes PHI permanently. For internal research or analytics, masking (specifically de-identification under HIPAA's Safe Harbor or Expert Determination methods) preserves data utility while protecting patient identity.
Financial services
PCI DSS mandates protecting cardholder data. Dynamic masking is common for internal systems where customer service reps see partial card numbers. But when financial records are produced for litigation or regulatory review, redaction permanently removes account numbers and PII from shared documents.
Legal
Law firms handling eDiscovery need to redact privileged information, trade secrets, and third-party PII from produced documents. The stakes are high -- improper redaction that leaves metadata intact or allows copy-paste extraction of "blacked out" text has led to court sanctions and malpractice claims.
Audit Trails and Legal Defensibility
For regulated industries, it's not enough to redact data, you need to prove what you redacted, why, and when. Proper redaction workflows include:
- Exemption and redaction codes documenting the legal basis for each redaction (e.g., FOIA Exemption 6, attorney-client privilege, HIPAA PHI)
- Timestamped audit logs showing who performed or approved each redaction
- Redaction copies that preserve the original unredacted file separately, maintaining chain of custody for legal proceedings
- Review trails documenting human oversight of AI-proposed redactions
Without these controls, redacted documents can be challenged in court or during regulatory audits. Organizations in government, law enforcement, and healthcare should treat audit trails as a non-negotiable requirement, not an optional feature.
Best Practices for Data Redaction and Masking
1. Classify your data first. Identify what types of PII you handle, where it lives, and who needs access. This determines whether redaction, masking, or both apply.
2. Match the method to the audience. If the data leaves your organization, redact it. If it stays internal but needs protection, mask it.
3. Don't rely on visual-only redaction. Black boxes over text in a PDF may look redacted but can sometimes be removed by copying the underlying text layer. True redaction must remove the data from the file, not just cover it visually.
4. Automate where volume demands it. Manual redaction works for a handful of documents. For hundreds of FOIA requests, thousands of body camera files, or ongoing call center compliance, AI-powered automation is the only practical approach.
5. Validate with human review. Automation catches the bulk, but human reviewers catch edge cases, especially for context-dependent PII that AI might miss or over-flag.
6. Document everything. Apply exemption codes, maintain audit logs, and preserve original files separately. If your redaction decisions are ever questioned, the documentation is your defense.
7. Test masking output. Verify that masked datasets don't allow re-identification through combination attacks, where multiple masked fields together can narrow down an individual.
How VIDIZMO Redactor Handles Multi-Format Redaction
Most data masking tools work exclusively with databases and structured data. Most redaction tools handle only documents or only video. The gap in the market is multi-format redaction, a single platform that processes video, audio, images, and documents.
VIDIZMO Redactor addresses this by combining AI detection across formats:
- Video redaction with object detection and tracking for faces, license plates, and screens -- including moving subjects across frames
- Audio redaction with spoken PII detection across 33+ categories in 82 languages, using configurable silence or tone replacement
- Document and PDF redaction with OCR for scanned files and handwritten text recognition
- Bulk processing tested at 1.1 million+ recordings, with fully automated, semi-automated, and manual workflow modes
- Audit trails with exemption codes, timestamped logs, and redaction copy generation for legal defensibility
The platform deploys as SaaS, government cloud (FedRAMP-aligned), on-premises, or hybrid -- meeting data residency requirements that cloud-only tools can't.
Contact us to see how VIDIZMO Redactor automates multi-format redaction.

About the Author
Jump to
Data Redaction vs Data Masking for Law Enforcement

How To Implement Redaction Without Losing Data Accuracy

No Comments Yet
Let us know what you think