by Ali Rind, Last updated: July 16, 2026

Recorded interviews, focus groups, and study visits are some of the hardest research data to de-identify, because the identifiers are faces, voices, and visible documents rather than fields in a table. Redaction is how you remove them before a recording is shared or reused. This guide covers what to redact in a human-subjects recording, why IRB consent requires it, and how to handle video, audio, and the transcript together.
A note on scope first. There is a separate guide on this site for PII redaction in usability test and UX research recordings, which covers corporate product research, where the consent regime is a company privacy policy and the recipients are product teams. This post is about IRB-governed academic and clinical human-subjects research: participants signed an IRB-approved informed consent, the recordings sit under research compliance obligations, and the recipients include collaborators, repositories, and secondary analysts under DUA terms. The modality work overlaps; the consent regime and compliance posture do not.
For where recordings fit in the wider research data lifecycle, see the researcher's guide to de-identifying sensitive data.
What do human-subjects recordings need redacted?
Recordings carry identifiers in five places a document tool never reaches.
Faces of the participants, of uninvolved third parties who pass through the frame, and of researchers who appear on camera. In multi-participant designs like focus groups, one recording captures several people whose consent terms may differ.
Voices of participants and researchers. Voice can identify a person even when the face is obscured, and spoken content carries the same identifiers text would: names, addresses, medical conditions, employer references, financial details.
Visible documents in the frame. Consent forms held up during a visit, screens behind the participant, paperwork on a table, name tags, identifying signage. The camera captures these incidentally.
Background environmental detail. A child's drawing on a refrigerator, family photographs, mail on a counter, identifying features of a home interior. In some designs the background reveals more than the participant says.
Referenced third parties who are not in the recording but are named in it, such as a participant naming their doctor, employer, or family member. Naming them brings them into the recording's identification surface.
A redaction pass that handles only faces leaves most of this untouched. Effective de-identification spans all five.
Why does IRB consent require redacting recordings?
Because the informed consent and the protocol made specific promises about how identifiable material would be handled.
The consent describes what secondary use is permitted, who will have access, and what retention and destruction conditions apply. Redacting recordings before sharing or secondary analysis is the mechanism that lets the team meet those promises while satisfying any downstream sharing obligation. The standard varies by study: some IRBs require full removal of faces, voices, and identifying content before any external sharing, while others permit specific identification when DUAs are executed and access is controlled. The protocol is the source of truth.
The Common Rule provides the federal framework, and international equivalents such as Canada's TCPS 2 and the EU Clinical Trials Regulation apply when the study or its collaborators sit outside the US. The principle is consistent across regimes: protect identifying information about human subjects except where consent and protocol explicitly authorize disclosure.
How to redact faces and bystanders in video
Video redaction for research recordings runs against the usual technical challenges, persistent tracking across frames, occlusion, lighting changes, with the added consent context.
Participant faces usually get blur or pixelation chosen for irreversibility, since a blur that image enhancement can undo is not adequate; permanent pixel-level redaction is. Whether a participant's face stays or comes out depends on what they consented to and what the recipient will do with the recording.
Uninvolved bystander faces come out regardless of the participant's consent, because their presence is incidental and the IRB's protection extends to any identifiable third party in the recording. Researcher faces sometimes appear in observational designs, and the protocol usually specifies whether researchers are identifiable in shared output.
Visible documents and identifying signage in the frame need text-level redaction. AI text detection in video frames identifies these regions and redacts them at the pixel level, with manual review confirming the catches. Persistent tracking is what makes the work tractable: a participant who turns toward the camera, away, behind someone, and back is the same person, and the redaction follows them rather than being marked frame by frame across a multi-hour recording.
How to redact spoken identifiers in audio
Audio carries the same identifier categories as text, in a modality where pattern matching is harder.
Transcription converts the audio to text first, then PII detection runs across the transcript to find spoken names, addresses, dates of birth, medical references, and employer mentions, producing a list of timestamps. Audio redaction applies a mute or bleep at those timestamps, keeping the surrounding conversation intact so a researcher coding for tone and flow still has usable data.
Speaker separation splits the audio by speaker, so a focus group recording can be handled per participant: one whose consent permits identification can stay while another in the same recording is redacted. Voice biometrics are a separate concern, since acoustic features can sometimes identify a speaker even with content removed; most research uses do not require voice-level anonymization, and when they do, voice transformation rather than redaction alone is the answer.
How to redact the transcript
Most qualitative research produces a transcript as a coding artifact, and it carries the same identifiers as the audio, in text where they are easier to detect.
The transcript pass is a document redaction workflow: PII detection runs across the text, the reviewer confirms catches and applies project-specific rules like study IDs and participant pseudonyms, and the redacted transcript becomes the artifact shared for secondary coding or deposit. The audio and the transcript both have to be redacted, and consistently. A transcript that reads "name removed" while the source audio still speaks the name is misaligned, and anyone working from both would see the gap. Workflow-level consistency across the two is what defensible recording de-identification produces.
How to prepare recordings for sharing or secondary analysis
The end-to-end workflow for a typical recording deposit:
Confirm what the IRB protocol permits and what the recipient requires, and document the decision. Process the recording through the pipeline: video gets face and bystander redaction with persistent tracking and text-level redaction of visible documents, while audio gets transcription, PII detection on the transcript, and redaction at the identified timestamps.
Review the output in a split-screen preview, confirming that participant faces match the consent decision, bystanders are consistently redacted, and audio identifiers are caught at the right points. Produce the redacted recording and redacted transcript as aligned, paired output. Log every redaction action with operator and timestamp in tamper-proof storage for IRB reporting and DUA documentation. The unredacted source stays in restricted institutional storage, retained per the approved plan; the redacted version is what gets shared.
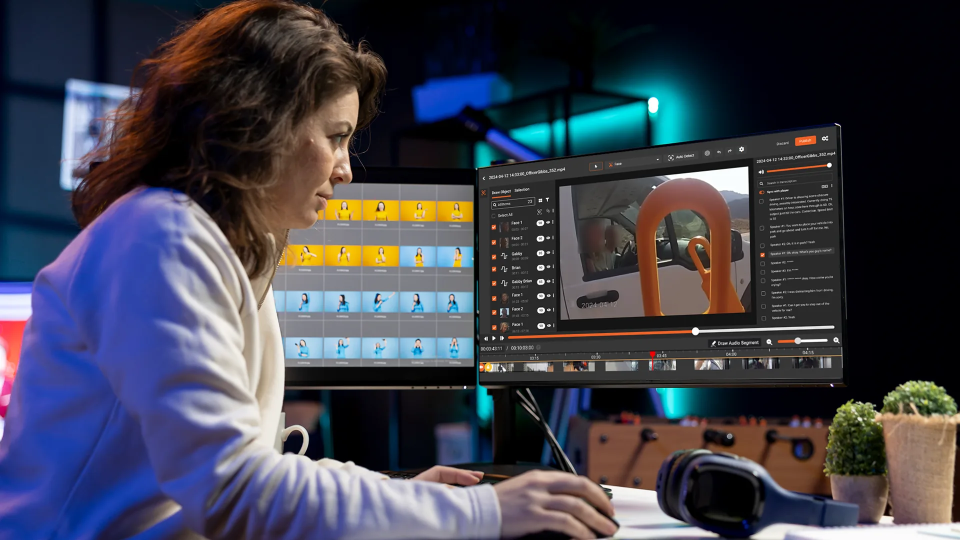
How VIDIZMO Redactor de-identifies research recordings
VIDIZMO Redactor handles both modalities in one workflow. Video redaction includes face and person detection with persistent tracking, text-area detection for visible documents in frame, and the redaction styles (blur, pixelate, black box) appropriate to research compliance. Audio redaction includes transcription with speaker separation, spoken PII detection across dozens of categories, and mute or bleep at identified timestamps. The transcript and the audio are processed as paired artifacts so redactions stay consistent across both, and tamper-proof audit logs record every action for IRB and DUA reporting.
For the video-only depth, see video redaction software. For audio-only, see audio redaction software.
Get research recordings ready to share
Redacting interviews, focus groups, or study-visit recordings before they leave your team? VIDIZMO Redactor handles video and audio in one workflow, with face and voice redaction, speaker separation, and audit logs for IRB and DUA reporting. If your team is at capacity, managed redaction services can process the recordings for you. Start a free trial or talk to our team.

People Also Ask
The workflow has three modality-specific steps. Video gets face redaction with tracking across frames, including incidental bystanders and any visible documents in the frame. Audio gets transcription, PII detection on the transcript, and mute or bleep at the timestamps where spoken identifiers occur. The transcript gets its own redaction pass so it stays consistent with the audio. The unredacted source stays in restricted storage.
The IRB protocol and informed consent set the requirement. Most protocols require de-identification of recordings before external sharing or secondary analysis, with the standard depending on what participants consented to. Some studies permit identification under controlled access; others require full removal of faces and voices. The Common Rule establishes the federal framework, but the IRB-approved protocol is the operational source of truth for any specific study.
Yes. Speaker separation splits the audio by speaker, so each participant is handled by their own consent terms, and video redaction with persistent tracking handles multiple faces in frame with per-person decisions on which stay and which come out. This matters for focus groups where consent terms differ across participants, so the recording does not have to be treated as a single uniform block.
Process them as paired artifacts from the same detection pass. The same identified identifiers are removed from the spoken audio at their timestamps and from the transcript text, so the two align. A transcript that reads "name removed" while the audio still speaks the name undermines the de-identification, so workflow-level consistency across both, rather than redacting each separately, is the standard.
About the Author

Jump to

How to De-identify & Redact Research Data Across its Lifecycle

How to Remove PII from AI and ML Training Data

No Comments Yet
Let us know what you think