by Ali Rind, Last updated: June 12, 2026

PII left in a training set does not stay in the training set. A model can memorize the names, numbers, and addresses in its training data and surface them later when prompted the right way, which turns a data-cleaning shortcut into a permanent property of the model. Removing that PII before training is a one-time cost; leaving it in is a cost that ships with every copy of the model.
This guide covers what happens when PII stays in training data, why it is worse than a database leak, where it gets in, how to redact it as a pipeline stage, the specific difficulty of unstructured text, and how data minimization complements the work. For the inference-time companion question of pasting records into a chatbot, see redacting medical records before uploading to AI tools. For where this fits in the wider research data lifecycle, see the researcher's guide to de-identifying sensitive data.
What happens if you leave PII in training data?
The model can learn the identifiers and reproduce them. Researchers have demonstrated training data extraction attacks that recover verbatim sequences, including names, phone numbers, and email addresses, by querying a model, and they found that larger models are more vulnerable than smaller ones. The phenomenon is called memorization, and it is more reliable for data the model saw repeatedly or for distinctive low-entropy sequences.
Training on a corpus that includes a patient name in a clinical note, a researcher's email in a comment thread, or an account number in a log creates a real chance the model surfaces that exact data later. The risk is not certainty, and not every model memorizes every identifier, but it is high enough that any institution training on potentially identifying data should address it upstream.
Why is PII in training data worse than a database leak?
A database leak is bounded and recoverable; a memorized identifier is neither.
A breach is identifiable, the affected records are enumerable, the notification scope is bounded by what left the database, and the remediation runs through credential rotation and access hardening. The incident has a closing.
A model trained on PII is different. The exposure is baked into the weights distributed to anyone who has the model. Removing the leaked information means retraining from a cleaned corpus, which means redoing the training run, redistributing the new model to every downstream consumer, and revoking the prior version. For widely released models, full revocation is impractical. That asymmetry is the whole argument for cleaning upstream: redaction before training is a one-time cost, while PII left in training scales with every downstream use of the model, and it carries GDPR or HIPAA exposure if the memorized data is regulated.
Where does PII get into training data?
PII enters training corpora from five common sources.
Scraped public text carries identifiers more often than people assume: researchers' email addresses in papers, contact details in HTML metadata, names and affiliations in proceedings. Public does not mean unidentifiable, and crawled web data routinely includes this content.
Clinical and educational narrative notes are the high-risk category for healthcare and academic institutions. Free-text fields in EHR systems, student case notes, and qualitative coding annotations are not automatically covered by the de-identification applied to structured columns, so names, record numbers, and dates can sit in the prose untouched.
Document corpora used for training carry identifiers in body text, attachments, document properties, and embedded images, where a scanned attachment holds identifiers as pixels that text-based detection does not see.
Application logs and telemetry pulled into training sets often contain user identifiers, IP addresses, session tokens, and customer references, and they are easy to pull in because engineering teams access them without the formal review that clinical or educational data goes through.
Sample data and test fixtures sometimes get rolled into corpora when development and production pipelines collapse together, carrying real-looking PII copied from production for realistic testing.
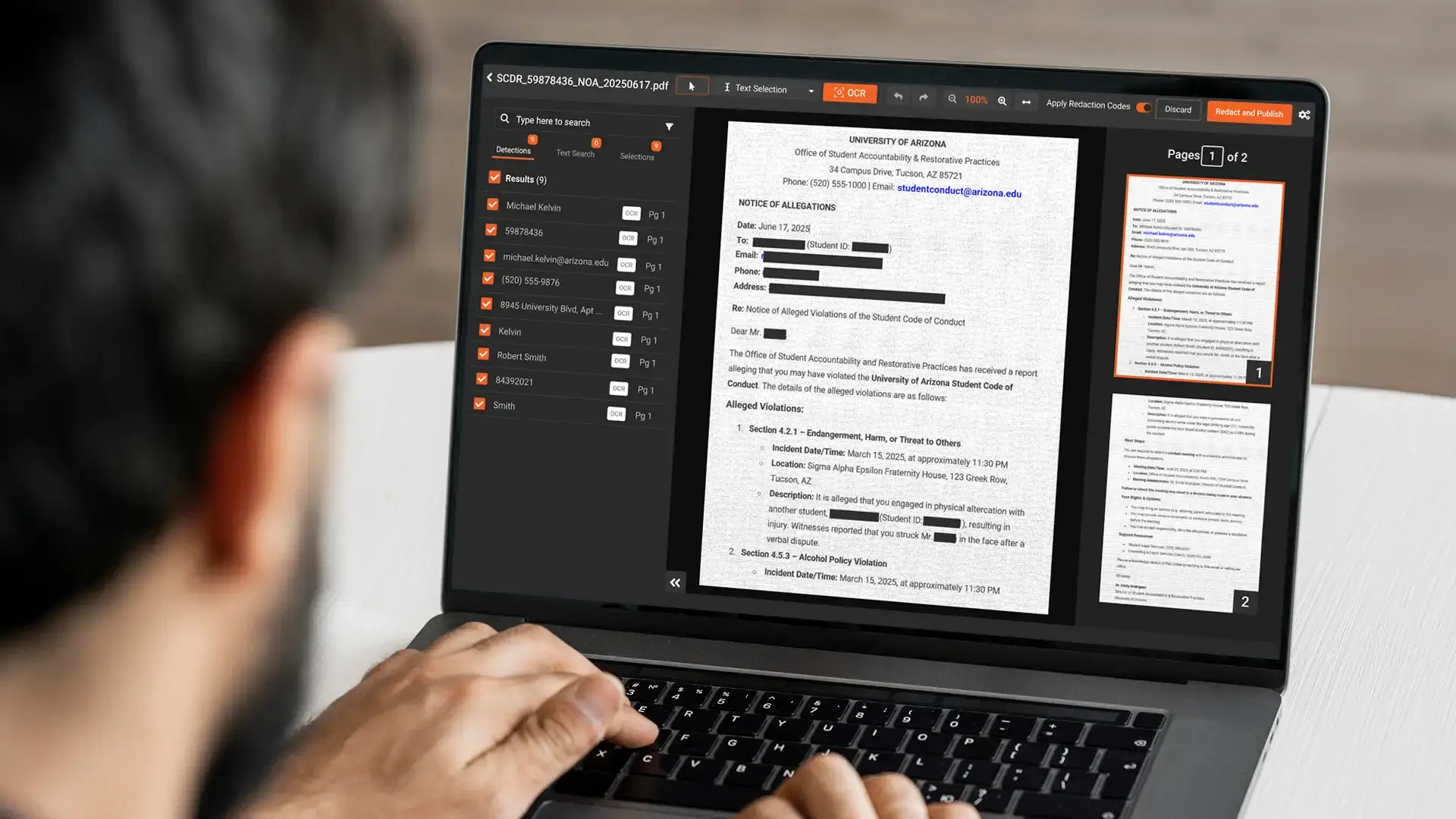
How to redact PII as a training-pipeline stage
Treat redaction as a pipeline stage that runs before the training job, with documentation of what was done.
Detection runs across the corpus to find PII. Structured fields can use rule-based pattern matching plus column-level policy; free-text needs named entity recognition tuned for the domain; embedded scanned content needs OCR before any text-level detection can work.
Redaction then applies to each detected instance, by removing the identifier, replacing it with a generic placeholder, or substituting a realistic synthetic value, with the choice depending on whether the model benefits from a structural placeholder or full removal.
Review runs before the cleaned corpus enters training. Sampling-based human review of the detection output confirms the catch rate and surfaces systematic gaps that need rule adjustment. It does not have to cover every example, but it has to cover enough to validate the pipeline.
The stage is repeatable. New data runs through the same step, and retraining produces a model built on a defensible dataset, with the audit log of the redaction stage serving as documentation of the privacy posture.
How do you redact PII in unstructured text?
Unstructured text is the hard case, because there is no schema telling you where the identifiers are.
A note reading "Pt John Smith, MRN 12345, seen today for f/u" carries identifiers in a format schema-aware tooling cannot parse. The redaction has to catch both the structural pattern (an MRN followed by digits) and the contextual entity (the name after "Pt"). Clinical NER models trained on medical text are the practical answer; see NER in healthcare for the technical depth.
Domain-general text needs general-purpose NER plus pattern rules for fixed-format identifiers like Social Security and account numbers, and general NER is materially less accurate at this than domain-tuned models, which is why corpus-specific tuning matters. Free-text fields embedded inside otherwise structured datasets, like a notes column, are an especially common gap: the structured fields get treated and the notes column gets exported as-is, so any text field needs explicit per-column review.
How data minimization reduces what you need to redact
The less identifying data you bring into the corpus, the less you have to redact.
Redaction handles the data that has to be there; data minimization asks whether it has to be there at all. GDPR Article 5 requires data minimization for personal data, and the principle reaches further than GDPR: the NIST AI Risk Management Framework treats it as part of trustworthy AI. At corpus preparation, the question is whether each field, record, and modality is necessary for the model's stated purpose.
An anomaly-detection model does not need the merchant name on a transaction; the amount, timing, and category carry the signal. A diagnosis-extraction model does not need patient identifiers; the symptom text and the label do. Removing unnecessary fields before training shrinks the PII surface without affecting performance for the intended use. Minimization shrinks the surface; redaction handles what is left.
How VIDIZMO Redactor scrubs PII from training corpora
VIDIZMO Redactor handles corpus-scale redaction across documents (native text and scanned via OCR), audio (via transcription and spoken PII detection), video, and image content. Detection covers dozens of PII categories with custom regex and context-word patterns for domain-specific identifiers like study IDs and institutional account formats. Bulk processing scales to corpora well beyond typical research training-set sizes, and audit logs of every redaction action document that the stage ran and what it caught.
For document corpora specifically, see AI-powered document redaction software. For the broader feature view, see the features page.
Train on clean data, not a liability
VIDIZMO Redactor scrubs PII from training corpora at scale across documents, transcripts, and scanned content, with detection for study-specific identifiers and audit logs of everything removed. If your team does not have capacity to run the pipeline, managed redaction services can prepare the corpus for you. Start a free trial or talk to our team.

About the Author

Jump to

How to De-identify & Redact Research Data Across its Lifecycle
Screen Recording Redaction for SaaS Marketing Videos

No Comments Yet
Let us know what you think