by Akhlaq Khan, Last updated: July 16, 2026
%20(1).webp)
To redact audio recordings means removing or masking spoken sensitive information so the file can be released, shared, or archived without exposing personal data. A 911 dispatch call, a body camera audio track, a deposition tape, a telehealth visit, or a customer service recording often contains names, addresses, account numbers, and other identifiers that have to be excised before the audio leaves the agency.
That is the part most outsiders underestimate. Audio is not paper. You cannot black out a sound the way you ink over a line of text. The waveform keeps playing whether you want it to or not, and every second of speech is potential evidence, potential exposure, or both. Manual audio redaction means a human listens to every minute, marks each PII utterance by hand, and renders a bleeped or muted version. For a one-hour call recording, that is typically four to eight analyst hours.
The pressure has been climbing. Body-worn camera mandates expanded across twelve more states in 2025, telehealth recording volume has held above pandemic-era levels into 2026, and FOIA and state public records request volumes continue to set records. Records teams, FOIA officers, and compliance leads are facing audio backlogs they cannot manually clear. This guide walks through what audio redaction actually is, why it is harder than document redaction, which spoken PII categories matter, and how a defensible workflow comes together.
Key Takeaways
- Audio redaction is the targeted removal or masking of spoken PII, PHI, and other sensitive content from recorded audio. It is distinct from transcript redaction and from simple muting.
- Manual audio redaction runs roughly four to eight analyst hours per hour of source audio. Automated detection collapses this to minutes for most call-recording and BWC workloads.
- Modern detectors handle 33 or more spoken PII categories, including country-specific identifiers like UK National Insurance, Indian Aadhaar, and Canadian SIN.
- Defensibility comes from the audit trail, not the redaction itself. Every action needs a timestamp, an operator, an exemption code, and a reversible audio layer for review.
- Compliance pressure spans HIPAA, PCI-DSS, GLBA, FOIA, CJIS, and emerging state privacy laws. A single workflow has to satisfy multiple regimes.
What Is Audio Redaction and How Does It Work?
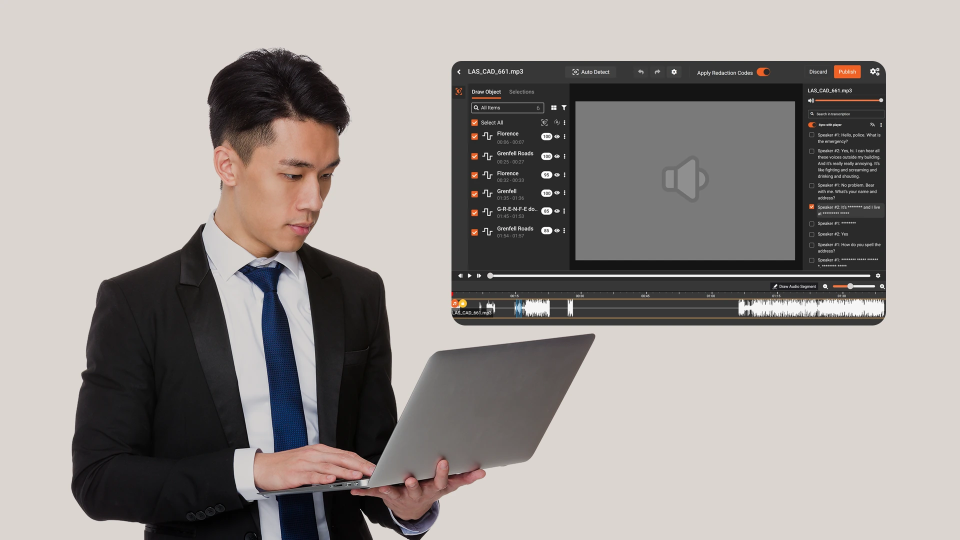
Audio redaction is the process of detecting, marking, and acoustically masking sensitive segments of a recorded audio file so the resulting copy can be released or used in contexts where the original cannot. The redacted segments are usually replaced with one of two outputs: silence (a mute) or a tone (a bleep). Either way, the rest of the conversation remains intact.
It helps to separate audio redaction from two adjacent activities people often conflate with it. Transcription redaction is editing a text transcript, which is helpful but leaves the underlying audio fully audible. Voice anonymization changes the speaker's vocal characteristics but does not remove the words they spoke. Audio redaction works at the segment level: a specific utterance becomes inaudible, and the rest of the audio is preserved.
In practice, mature audio redaction software maintains three synchronized artifacts: the original audio (frozen as evidence), the redacted audio (the release copy), and a redacted transcript (for indexing, search, and review). The transcript and audio are time-aligned, so a reviewer can scrub a flagged passage instead of listening to the entire file. That alignment is what makes large-scale audio redaction tractable at all.
Why Audio Redaction Is Harder Than Document Redaction
Three structural problems make audio redaction harder than redacting documents, and any team building a workflow has to plan around them.
First, audio is temporal. A document has fixed coordinates. Page seven, paragraph two, line three is going to be there forever. Audio PII is bound to a moment, often a fraction of a second, and a small error in start or end timing either leaks the PII or chops surrounding words that the public has a right to hear. Frame accuracy matters.
Second, audio is acoustic. Speech overlaps, agents talk over callers, sirens cut in, depositions have multiple counsel speaking at once. Pattern matching on text does not work on raw audio. The pipeline has to transcribe the audio, identify the speaker, find the PII span in the transcript, then map the span back to the precise audio timestamps. Each step has its own error rate, and errors compound.
Third, audio is voluminous. A police department with 800 officers can generate 30,000 or more hours of body camera audio per month. A mid-size contact center records 15,000 to 20,000 calls per day. A manual workflow does not scale, and a partially automated one falls apart at peak load. From what we have seen, the only sustainable answer is a fully automated detection layer with a sampled human review stage on top.
Which Audio Recordings Need Redaction Most Often?
Different recording categories carry different PII risk profiles, and the redaction approach has to fit the audio source.
Call center recordings
Customer service, collections, and sales calls contain spoken credit card numbers, CVVs, SSNs, account numbers, and account passwords. Under PCI-DSS, these recordings cannot be retained in unredacted form when cardholder data is captured. See our deeper guide on PCI-DSS audio redaction for call centers.
911 and dispatch audio
Callers state addresses, names, phone numbers, and sometimes medical information. State open records statutes vary, but most require redaction of victim and reporting party identifiers before release. Agencies handling these workloads tend to standardize on sheriff's office audio redaction workflows to keep up with PIA and FOIA deadlines.
Body-worn camera audio
The audio track of BWC footage frequently contains witness names, juvenile identifiers, suspect statements, and medical information overheard at scenes. California AB-748 and similar laws require timely release with PII removed. Most agencies handle this alongside the video track through dedicated body camera redaction workflows.
Witness interviews and depositions
Counsel names parties, addresses, account numbers, and case-protected information that has to be removed for sealed-record releases.
Telehealth and clinical consultations
HIPAA-protected health information appears throughout. Recordings used for training, quality review, or research need PHI removed before secondary use. For broader PHI handling beyond audio, see PHI redaction for healthcare workflows.
Internal investigations
HR interviews, ethics line recordings, and corporate compliance calls reference third-party names and confidential business information that has to be scrubbed before broader disclosure.
Each of these categories has its own retention rules, response deadlines, and exemption frameworks. A workflow built only for one source rarely transfers cleanly to another. We have seen agencies try to use document-redaction tools for BWC audio and end up reverting to manual workflows after six months, when the throughput math stops working.
Which Spoken PII Categories Should an Audio Redaction System Detect?
Not every PII category appears in audio with the same frequency. A redaction system has to cover the identifiers people actually say out loud, not the ones that live in form fields and document metadata. Detection coverage is one of the easiest specs to compare across solutions, so it deserves attention up front.
- Personal identifiers spoken on every call: full names, dates of birth, home addresses, phone numbers. These are the workhorses of identity verification and show up in nearly every call center, 911, and telehealth recording.
- Financial identifiers spoken during payment and verification: credit card numbers, CVVs, bank account numbers, routing numbers. PCI-DSS and GLBA workloads center on catching these.
- Government identifiers spoken during onboarding and benefits checks: Social Security numbers, driver's license numbers, passport numbers, country-specific national IDs like UK National Insurance, Indian Aadhaar, and Canadian SIN.
- Healthcare identifiers spoken during clinical and telehealth conversations: patient names tied to diagnoses, medical record numbers, prescription numbers, health plan beneficiary numbers. HIPAA workloads turn on these.
One thing worth flagging: the regulatory definition of PII varies by jurisdiction. California's CCPA, the EU's GDPR, and the federal HIPAA Privacy Rule under 45 CFR 164.514 each define identifiers differently. A redaction policy that satisfies one may under-redact for another. Multi-jurisdiction operations need a configurable category set, not a fixed one.
How Does Automated Audio Redaction Work in Practice?
Under the hood, modern audio redaction is a four-stage pipeline. Understanding the stages helps explain where errors come from and where review effort is best spent.
Stage 1: Transcription. The audio is converted to text with timestamps at the word level. Quality of this stage drives the entire pipeline. A 5 percent transcription error rate cascades into 5 percent under- or over-redaction. Word error rates vary by language and audio quality, and the strongest production systems benchmark in the 3 to 8 percent range for clear English audio.
Stage 2: Named Entity Recognition. The transcript is processed by NLP models that flag PII spans. Generic NER finds names and addresses, pattern detectors handle structured identifiers like SSNs and credit cards, and LLM-based extractors catch context-bound entities such as case numbers preceded by phrases like "case file" or "incident report." A confidence score attaches to each detection.
Stage 3: Mapping. Each flagged span is mapped back to its audio timestamps. This is where speaker diarization matters: if a caller and an agent are both speaking, the redaction layer needs to know which speaker said the PII, and whether overlapping speech requires partial masking.
Stage 4: Rendering. The redacted segments are replaced with either silence or a tone, and a new audio file is produced. The original is preserved as evidence, and a layered redaction record stores every action with a timestamp, operator ID, and exemption code.
From what we have seen, the right place to invest review effort is the transition between Stage 2 and Stage 3. Confidence thresholds in the 50 to 70 percent band typically generate manageable review queues. Lower thresholds increase false positives and waste review time. Higher thresholds risk missed PII. The right setting depends on whether the workload is regulated PCI or PHI (where over-redaction is preferable) or public records (where over-redaction draws legal challenges).
Common Misconceptions About Automated Audio Redaction
Three concerns come up in almost every evaluation. Each one is worth addressing directly:
"Speech recognition is too unreliable for compliance work." Modern speech-aware systems are designed for detection with human review, not blind release. Word error rates have fallen into the 3 to 5 percent range for clear English audio since 2024, narrowing the historical accuracy gap that justified manual workflows.
"Automation removes human control." Review and approval stay central to a defensible workflow. Confidence thresholds in the 50 to 70 percent band route uncertain detections to human reviewers; automation prepares redactions, it does not finalize them.
"Manual listening is safer." At scale, reviewer fatigue and inconsistency make manual review riskier than calibrated automation with sampled QA. The risk profile flips somewhere between 20 and 50 hours of audio per week, depending on team size and training.
How to Build a Defensible Audio Redaction Workflow
Detection accuracy is only one piece of a defensible workflow. The other half is the procedural and audit-trail layer that turns a redacted file into a release-ready record. A common mistake is treating audio redaction as a single processing step, when in reality it is a chain of accountable handoffs.
A workflow that holds up under audit or litigation includes the following:
- Intake and identifier. Each file gets a case or request ID at ingest. The original audio is sealed and a hash recorded.
- Transcription and detection. Automated pipeline produces a redaction layer. Detected spans are tagged with PII category and confidence.
- Reviewer queue. Low-confidence detections and high-stakes categories (PHI, PCI, juvenile identifiers) route to a human reviewer.
- Exemption coding. Each redacted span is mapped to a legal basis. For FOIA releases, the (b)(6) and (b)(7)(C) exemptions are the most common. For HIPAA, the basis is 45 CFR 164.514. State open records laws have their own exemption code sets.
- Quality assurance. A second reviewer spot-checks a sample, listening to flagged spans and confirming the redaction style.
- Render and release. The released audio file is generated, watermarked if needed, and delivered.
- Audit trail. Every action (open, listen, redact, approve, release) is logged with timestamp, user, and exemption code. The audit trail is the record of due care.
A reasonable rule: if the audit log cannot answer "who redacted what, when, and why," the workflow is not defensible. NIST SP 800-86 outlines forensic integrity principles that apply directly to redacted media handling, and the same principles map onto our own redaction log best practices.
How VIDIZMO Redactor Handles Audio Redaction at Scale
VIDIZMO Redactor runs the full four-stage pipeline (transcribe, detect, map, render) with configurable confidence thresholds and speaker diarization, so PII spoken by one party can be redacted while the other side of the conversation remains intact. The detector covers 33 or more spoken PII categories across 82 transcription languages, with translation into 74 languages for cross-border review.
For high-volume environments, the platform processes bulk batches in excess of 1.1 million recordings through queue-based, off-hours automation. Admin-configured auto-redaction policies let a contact center apply PCI rules to one queue and HIPAA rules to another without rebuilding the workflow per file. The multi-layer architecture preserves the original audio while producing the release copy, so reviewers can roll back or adjust redactions without re-running detection.
Start your free Redactor trial and test audio redaction on your own recordings.

Why Audio Redaction Is Now a Core Privacy Workflow
Audio redaction is no longer a niche workflow buried in a back-office records office. It is one of the core privacy operations for any organization that records calls, fields public records requests, or runs telehealth at scale. The work is harder than document redaction, the volume is higher than most teams forecast, and the regulatory map is unforgiving.
The pattern that holds up: automate detection across the right spoken PII categories, route confidence-bounded outputs to a sampled human review, and instrument every action in an audit trail that ties redactions to legal exemption codes. Get the audit trail right and the rest of the workflow becomes auditable, defensible, and scalable. Skip it and the best detector in the world will not save you when the release is challenged.
If you want to see how this comes together in production, explore the Redactor audio redaction workflow or run a free trial against a sample of your own recordings. Adjacent pillar guides on FOIA video redaction, document redaction at scale, and bulk media processing pick up the parts of the operation that sit on either side of the audio pipeline.
If you want to see how this comes together in production, explore the VIDIZMO Redactor audio redaction workflow or start a free trial against a sample of your own recordings.
People Also Ask
Audio redaction is the targeted removal or acoustic masking of spoken sensitive information in a recorded audio file. The protected segments are replaced with either silence or a tone, while the rest of the recording remains intact. It is used for compliance with privacy regulations, public records laws, and litigation discovery requirements.
Transcription redaction edits the text transcript but leaves the original audio fully audible. Audio redaction operates on the waveform itself, so the spoken words are not retrievable from the released file. Most modern systems generate both a redacted transcript and a redacted audio file in time-aligned pairs, and platforms like VIDIZMO Redactor maintain those artifacts in sync for review.
Yes. Modern AI pipelines process thousands of recordings per day with limited human review. The constraint is not throughput, it is the policy and review configuration. From what we have seen, production deployments routinely handle 50,000 to 100,000 audio files per month, and bulk batches over a million recordings are within reach when the workflow is properly configured.
Production-grade systems detect 33 or more categories including names, addresses, phone numbers, dates of birth, SSNs, credit card numbers, CVVs, account numbers, passport numbers, VINs, usernames, passwords spoken aloud, IP addresses, medical record numbers, and country-specific identifiers like UK National Insurance, Indian Aadhaar, and Canadian SIN. Custom regex and context-word patterns extend detection to organization-specific identifiers like case file numbers.
Defensibility depends on the audit trail, not the detector alone. A defensible workflow records who reviewed each detection, what exemption code was applied, and preserves the original audio under chain of custody. Courts have accepted automated redaction outputs in FOIA litigation when the agency could produce a complete audit log. The detector is one input, the audit trail is what holds up under cross-examination.
Manual audio redaction typically runs four to eight analyst hours per hour of source audio. Automated detection with sampled human review collapses the same work to minutes per hour, depending on confidence thresholds and reviewer staffing. The accuracy gap has narrowed since 2024 as transcription word error rates fell into the 3 to 5 percent range for clear English audio, removing one of the historical objections to automation.
Audio redaction platforms typically offer SaaS (shared or dedicated tenancy), government cloud for federal and law enforcement workloads, on-premises for agencies with data sovereignty constraints, and hybrid for split workloads. The right choice depends on data residency, classification, and integration requirements. For agencies handling criminal justice information, an Azure Government Cloud deployment is usually the right default because it satisfies CJIS controls without rebuilding the application stack.
About the Author
Jump to
Audio Redaction Services for Call Centers and Legal Teams
.webp)
How Insurance Companies Can Redact PII in Video & Audio Files

No Comments Yet
Let us know what you think