by Ali Rind, Last updated: May 13, 2026

Most redaction failures come down to a single misunderstanding: the person redacting confused hiding information with deleting it. A black rectangle drawn over a name in a PDF looks identical to a properly redacted page on screen. The difference only becomes visible when someone selects the area, copies it, and pastes the original text into a notepad. Forensic analyses by the PDF Association have shown that the underlying mechanics of these failures have not changed in nearly two decades.
That gap, between what a document looks like and what it actually contains, is where almost every public redaction failure has happened. The same mistake keeps recurring across court filings, regulatory disclosures, FOIA responses, body-cam releases, and enterprise data sharing, often involving teams with no shortage of legal or technical expertise. The cost is rarely the redaction itself. It is the exposure that follows: sealed witness identities revealed, trade secrets handed to opposing counsel, patient records published, security procedures leaked.
This post walks through five real-world redaction failures from the last fifteen years, the underlying mistake behind each one, and the workflow changes that would have prevented them. The cases span legal filings, government disclosures, public records video, and healthcare records, because the failure modes are consistent across all of them.
What Is a Redaction Failure, Exactly?
A redaction failure happens when information that was meant to be permanently removed from a document remains recoverable. The visible content looks redacted. The underlying data is not.
This can happen at the text layer of a PDF, inside file metadata, in embedded objects, in hidden spreadsheet rows, in audio that was muted too late, in video frames where a face was masked in 99 of 100 frames, or in image files where a blur can be partially reversed. A failure does not require sophisticated forensics to exploit. In most of the cases below, the sensitive information was recovered by a journalist or researcher using nothing more than copy and paste.
5 Real-World Redaction Failures
1. Paul Manafort court filing (2019): black-box overlay on a legal document
In January 2019, attorneys for Paul Manafort filed a response to special counsel allegations that contained sections marked as redacted. The filing was submitted as a PDF with black rectangles drawn over the sensitive portions. A Guardian reporter copied the redacted text and pasted it into a separate document, which revealed material the defense had intended to keep sealed, including details of campaign data sharing with a Russian associate. The story ran globally within hours, and the American Bar Association Journal used the incident as a teaching case for how lawyers should approach PDF redaction.
The mistake
The black rectangles were annotations placed on top of the text layer, not a true redaction. The underlying text stream remained intact and searchable inside the PDF.
How to prevent it
Use a redaction tool that removes the text from the content stream and flattens the document before saving. After redacting, run a copy-paste verification test on the released file. For legal teams handling sealed filings, evidence, and privileged material, this is exactly the workflow gap that redaction software built for legal proceedings is designed to close.
2. TSA airport security manual (2009): federal-scale copy-paste exposure
The Transportation Security Administration published a 94-page operations manual on a federal procurement website. Sections marked as "Sensitive Security Information" were obscured with black rectangles in the PDF. Within hours of publication, researchers extracted the underlying text and posted screening procedures, exemptions for diplomats and intelligence personnel, and details of physical security protocols. As CBS News reported at the time, the redactions could be stripped by anyone with basic familiarity with Adobe Acrobat. The TSA was forced to revise screening procedures at airports across the country.
The mistake
The same black-box overlay approach used in the Manafort filing, applied to a far more sensitive document with a much wider distribution.
How to prevent it
Any document containing classified, sensitive, or restricted-distribution content needs to be processed through a redaction tool that removes content rather than hiding it, followed by a verification step before publication.
3. EU-AstraZeneca vaccine contract (2021): surviving PDF bookmarks
When the European Commission published its COVID-19 vaccine supply contract with AstraZeneca, commercial terms including pricing, delivery schedules, and indemnification clauses were redacted in the body of the document. The redactions held on the visible page. The PDF bookmarks did not. As The Register first reported, section bookmarks in the document outline pointed directly to the labeled headings of redacted sections, and clicking through revealed the underlying structure and, in several places, the surrounding text.
The mistake
The redaction workflow covered the visible content but did not regenerate or strip the PDF's navigational metadata, including bookmarks, hyperlinks, and outline entries.
How to prevent it
A complete redaction process has to include bookmarks, the document outline, embedded links, comments, and any other navigational metadata. Flatten the document after redaction so that no auxiliary structure persists.
4. Healthcare records shared with surviving file metadata
A recurring failure pattern in healthcare data sharing involves providers redacting the visible content of a record before sending it to a research partner, insurer, or attorney, but leaving the file metadata intact. Author names, original filenames containing patient identifiers, revision history showing earlier unredacted drafts, and EXIF data from embedded scans persist after the visible text has been redacted. In smaller patient populations, exposed metadata is often enough to reidentify a patient even when the visible record contains no direct identifiers.
The mistake
Treating redaction as a visible-text exercise rather than a whole-file exercise.
How to prevent it
Every redaction workflow handling regulated data needs an automatic metadata scrub step. Author, title, subject, comments, revision history, and embedded image EXIF data all need to be cleared before the file leaves the system. Pattern-based redaction helps with the related problem of consistently catching PII like medical record numbers, dates of birth, and patient IDs across the visible content itself.
5. Body-camera footage releases with surviving identifiable details
Public records releases of body-camera footage have repeatedly produced videos where the primary subject's face was blurred but other identifiers remained visible. Reported failure modes include a clear reflection of the subject in a vehicle window, a name visible on an officer's bodycam display, a license plate readable in one of several hundred frames, and a bystander's face left unblurred because automated tracking lost the subject for two seconds. In each case, the agency released the video believing the redaction was complete.
The mistake
Visual redaction in video is multi-frame, and any tool that only tracks the obvious subject will miss reflections, secondary subjects, and frames where tracking drops.
How to prevent it
Use video redaction software that applies AI object detection to faces, license plates, screens, and paperwork across every frame, not only the primary subject. Run a manual review pass on representative frames before release, including the first and last frames of any tracked object and any frame where the tracker reinitialized. Agencies handling regular public records requests should build this into a standardized FOIA redaction workflow rather than treating each release as a one-off project.
The Multi-Format Problem Most Guidance Misses
Most published guidance on redaction focuses on PDFs. Real workflows do not stop at PDFs. A single matter can involve text documents, spreadsheets, scanned images, body-cam video, recorded interviews, screen recordings, and chat exports. Each format has its own failure modes, and a redaction process built for one format will miss the others.
For video, the failure modes are multi-frame tracking gaps, reflections, secondary subjects, and on-screen text. For audio, they are timing precision, transcript-level PII detection, and voice identity. For images, they are EXIF data, reversible blur, and content visible in unmasked corners of a frame. For spreadsheets, they are hidden rows, pivot caches, and named ranges. For chat exports and email threads, they are quoted replies, attachments, and embedded headers.
A redaction workflow that cannot handle every format the team will encounter is a workflow that will fail at the format the team did not anticipate.
A 10-Point Pre-Release Redaction Checklist
Before any redacted file leaves your system, run through this list. It catches the failures in the cases above and most of the ones not in this post.
- The redaction tool used removes content from the file, not from the visible layer only.
- The file has been flattened after redaction so that no annotation layer remains.
- All file metadata has been stripped, including author, title, comments, and revision history.
- PDF bookmarks, hyperlinks, and outline entries have been removed or regenerated to remove references to redacted content.
- Embedded objects, attachments, and form fields have been reviewed and redacted or removed.
- For spreadsheets, all hidden rows, columns, sheets, and pivot caches have been deleted, not hidden.
- For video, every frame has been reviewed for reflections, secondary subjects, and tracking gaps, not only the primary subject.
- For audio, redacted segments include a buffer on both sides, and the transcript has been reviewed for PII detection.
- The released file has been opened in a fresh session and tested with copy-paste, search, and unhide-all checks.
- An audit log of what was redacted and why has been retained, separately from the released file.
How Purpose-Built Redaction Software Closes These Gaps
Most of the failures in this post happened because the redaction was performed in a general-purpose tool that was never designed for permanent content removal. PDF annotation tools, image editors, basic video editors, and spreadsheet software all support visual redaction, and all of them produce files that look redacted while leaving the underlying data intact.
VIDIZMO Redactor is built for the cases general-purpose tools miss. It performs content removal across PDFs, documents, images, video, and audio in a single workflow. AI-powered detection identifies categories of PII including names, addresses, phone numbers, social security numbers, license plates, and faces, and applies redaction at the data level rather than as an overlay.
Metadata is stripped automatically. Video redaction tracks faces and license plates across every frame with manual review for edge cases. Audio redaction operates at the transcript level with timing buffers around each redacted segment. An audit log records every redaction action for defensibility. For teams handling regulated data across multiple file formats, this is the workflow most redaction failures have come from not having.
Every failure in this post started with the wrong tool. Try VIDIZMO Redactor and remove the data, not just the view.

About the Author

Jump to
How to Redact an Email the Right Way
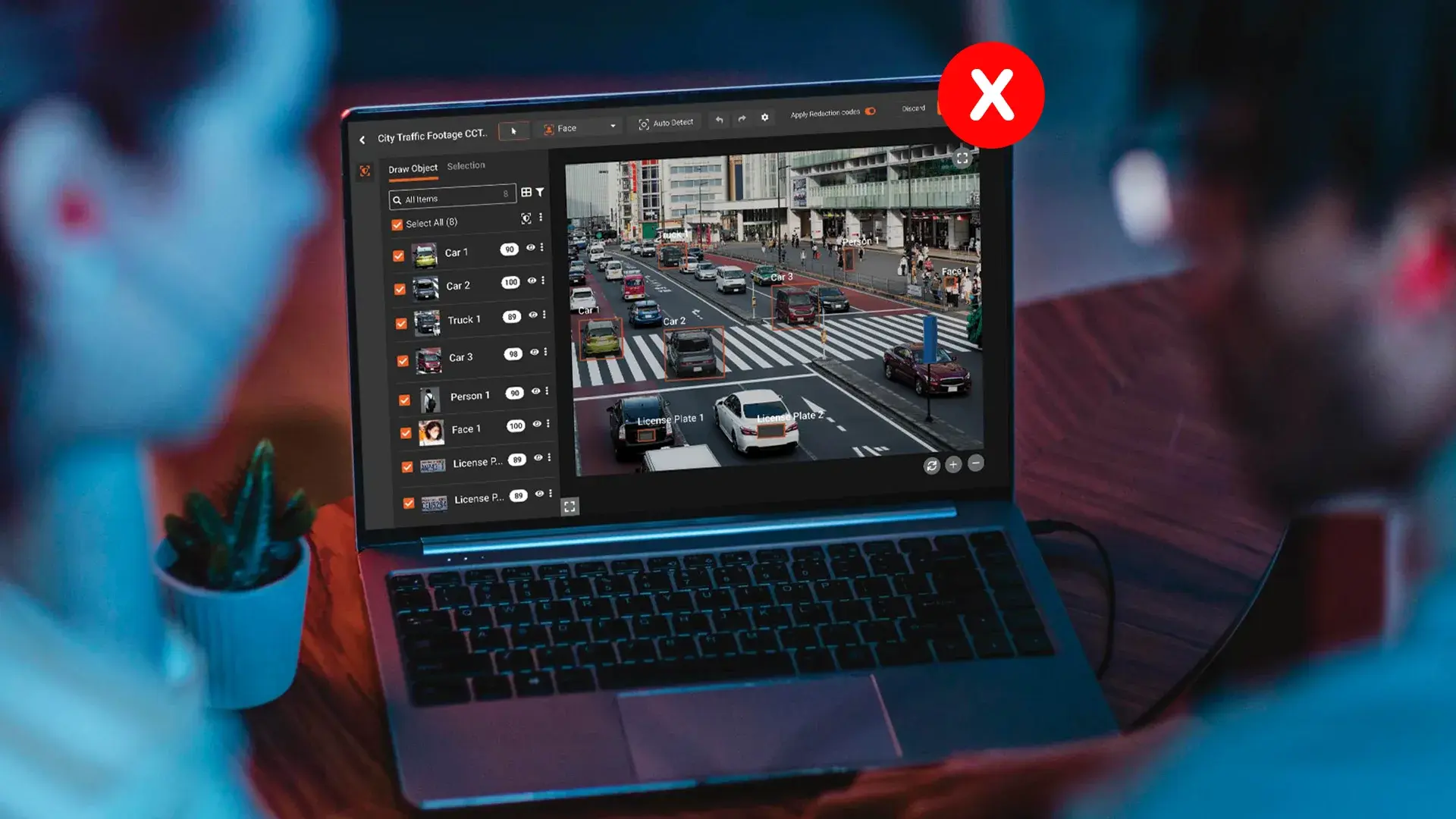
Why Redactions Fail: 7 Common Mistakes That Cause Data Exposure


No Comments Yet
Let us know what you think