by Ali Rind, Last updated: July 16, 2026
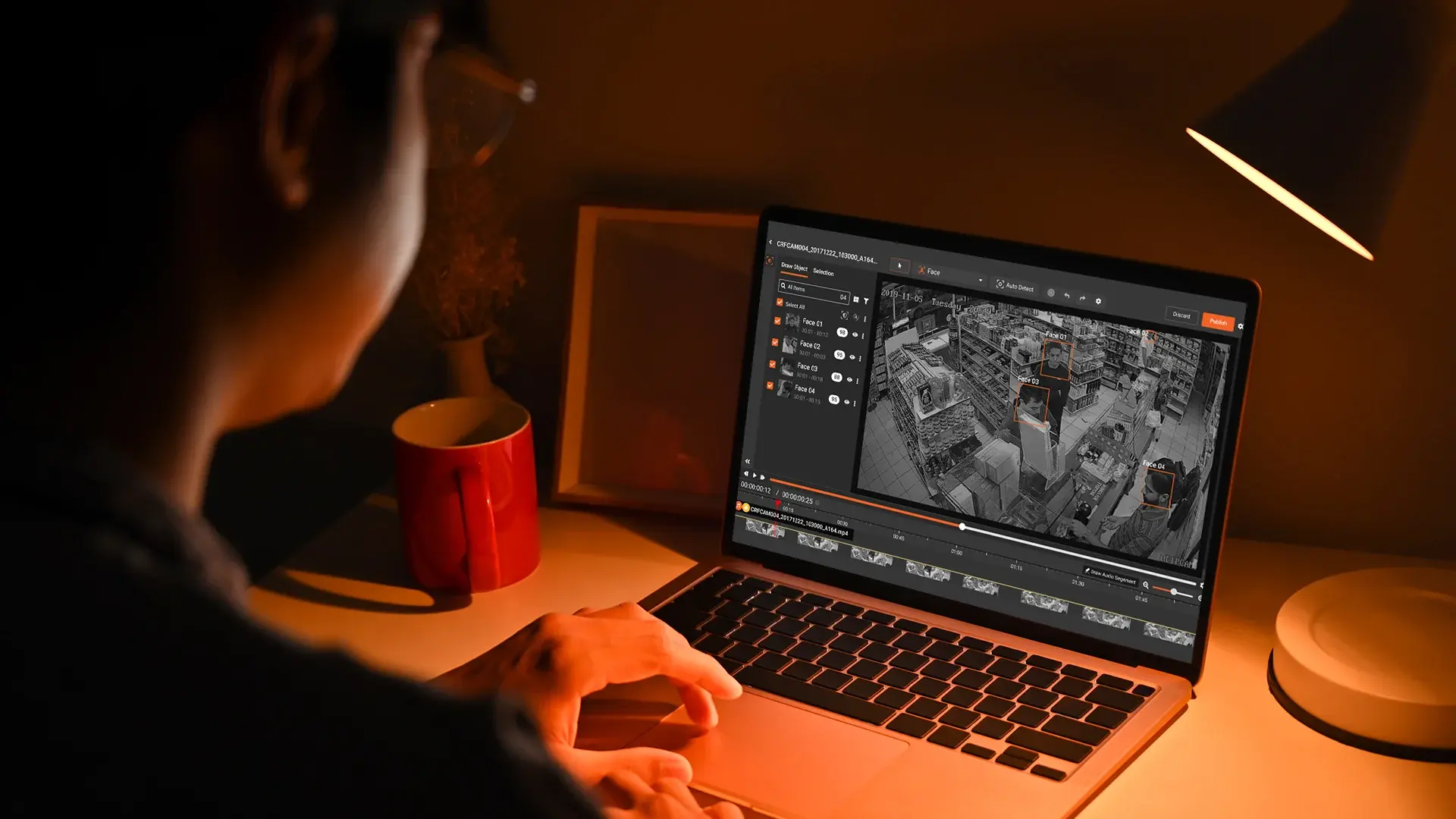
A legal filing was submitted to a US federal court with several names redacted behind black boxes. A journalist opened the document, selected the text beneath one of the black marks, and pasted it into a text editor. The names appeared in full.
The document was never actually redacted. A black box had been drawn over the text. The text was still in the file.
This is not a technical edge case. It is what happens with overlay redaction, and it is what most people are using today.
Understanding the difference between permanent redaction vs overlay redaction is not a niche technical concern. It determines whether your redacted documents are compliant or whether they contain recoverable personal data with a black box drawn over it.
The Assumption That Gets Organisations Into Trouble
When most people redact a document, they assume the result is the same regardless of which tool they use. They apply a black box. They save the file. They send it.
The assumption: the data underneath is gone.
With overlay redaction, that assumption is wrong. The data is still in the file. It is still in the document's text structure. It may be in the metadata. And recovering it requires no specialist knowledge. In many cases, nothing more than a copy and paste is enough.
This has caused documented data breaches, court sanctions, and regulatory findings. The problem is not rare. It is widespread, because the visual output of overlay and permanent redaction looks identical.
What Overlay Redaction Actually Does
When you draw a black rectangle over text in a standard PDF editor or word processor, you are adding an annotation layer to the document. Think of it as placing a sticker over text on a printed page.
The content underneath is unchanged. In a PDF, the document's text stream remains intact. The annotation layer simply instructs the viewer to display a black box at that coordinate. Remove the annotation, and the original text reappears.
In practice, anyone can recover overlay-redacted content by:
- Copying and pasting the text from the PDF into any text editor
- Opening the file in a tool that strips annotation layers
- Using a PDF viewer's Edit mode to select or delete the black rectangle
- Parsing the file's raw structure with freely available tools
None of these methods require technical expertise. Most take under a minute.
The problem extends beyond visible text. PDF files contain metadata that may include author names, revision history, tracked changes, and document properties. An overlay redaction approach typically leaves this metadata untouched, creating an additional source of recoverable data beyond the visible text. This is why purpose-built tools designed to handle metadata and hidden data redaction are essential for any compliance workflow.
What Permanent Redaction Actually Means
Permanent redaction removes the identified content from the document's underlying data structure. The text is not hidden. It does not exist in the output file.
In a permanently redacted document:
- The text is removed from the document's content stream
- The position previously occupied by the text may display a neutral placeholder (a black box, a white space, or nothing)
- The document is rebuilt as a new file without the identified content
- The output cannot be deconstructed to reveal the original data because the original data is not present
You cannot recover content from a permanently redacted document by removing annotations, because there are no annotations over live text. The content was removed during processing.
The visual output looks the same. A black box appears in both cases. The difference is in the file structure, not the appearance.
For a plain-language breakdown of what redacted text really means and the methods used to do it correctly, see our guide on redacted text explained.
Why This Distinction Matters for Compliance
Regulations including GDPR, UK GDPR, HIPAA, and CCPA require that personal data shared externally is genuinely protected. Producing a document that appears redacted but contains recoverable personal data does not satisfy these requirements.
Consider three common scenarios:
FOIA and public records requests. A government body redacts a document before release. If the redaction is an overlay, any recipient can recover the withheld information. The disclosure has effectively occurred, regardless of the black boxes. Government agencies managing FOIA workflows face particular exposure here. Our guide on how government agencies can safely redact sensitive documents covers the correct process in detail.
Clinical trial document sharing. A research site shares source documents with a pharma sponsor before a monitoring visit. Patient names and NHS numbers are apparently redacted. If the underlying text is still in the file, the sponsor has received identifiable patient data, creating a potential GDPR breach. For teams working with medical records and participant data, our guide on how to redact PHI in medical records for clinical research explains the standards that apply.
Legal discovery and eDiscovery. A law firm produces documents with redactions. Opposing counsel recovers the withheld content using standard tools. The firm has disclosed privileged or protected material, with potential sanctions consequences. Legal teams can find practical guidance on avoiding these failures in our overview of redaction software for legal and compliance workflows.
In each case, the organisation believed its data was protected. It was not.
Is Adobe Redaction Permanent?
Adobe Acrobat Pro includes a Redact tool that can produce permanent redaction. The key word is "can."
The process requires two steps:
- Mark content for redaction (places a visual overlay on the document)
- Click "Apply Redactions" (permanently removes the underlying content and rebuilds the file)
Step one alone does not produce a permanently redacted document. It produces a document with redaction marks applied as annotations. The underlying text is still there.
Many users mark content and save the file without applying redactions. The document looks redacted. Someone opens it and copies the text. The unredacted content appears.
Adobe does prompt users to apply redactions before closing, but the workflow is not self-evident. This is a documented, common failure mode, not a theoretical risk.
Standard Microsoft Word and Google Docs have no permanent redaction capability. Highlighting text in black, changing font colour to black, or drawing a shape over text are all overlay methods. The content is visually hidden and structurally unchanged.
How to Check Whether Your Tool Is Doing Permanent or Overlay Redaction
Test your current process on a non-sensitive document:
- Apply a redaction to a section of text using your normal tool
- Save and close the file
- Reopen it
- Attempt to select and copy text beneath the redaction mark
- Paste the copied text into a plain text editor
If text appears in the text editor, your tool produced overlay redaction. The data was never removed.
If no text copies from beneath the mark, the tool may have performed permanent redaction. For added confirmation, open the file in a raw text reader or PDF inspector and search for the redacted terms.
What to Look For in a Permanent Redaction Tool
If your organisation redacts documents for compliance purposes, the tool must produce output where the identified data genuinely does not exist in the file.
Key requirements:
Data removal, not concealment. The output file must not contain the redacted content in recoverable form. This applies to the document's text stream, not just the visual layer.
OCR for scanned documents. Many compliance documents are scanned images, including patient records, court filings, and historical records. Redacting a scanned PDF requires converting image content to machine-readable text before detection can occur. Without OCR, a text detection tool will find nothing to redact in an image-based file.
Natural language processing for contextual identifiers. Pattern matching catches structured data like Social Security numbers and email addresses. It misses names and dates embedded in narrative text. Purpose-built tools use natural language processing to identify contextual identifiers in prose.
Audit trail. Every redaction decision should be logged with the identifier type, document reference, timestamp, and reviewer. This log supports regulatory review and responds to data subject enquiries.
Original preservation. The redacted output should be a separately generated file. The original must remain intact in a secure location.
For a detailed look at how these capabilities are applied in practice, see our comparison of the best AI redaction software for sensitive data in files.
How VIDIZMO Redactor Handles This
VIDIZMO Redactor is a purpose-built redaction platform. When processing a document, Redactor generates a new output file with identified content removed. The original is preserved separately. The output does not contain the redacted data behind a visual layer. The content is removed during processing.
For scanned documents, Redactor uses OCR to convert image-based content to searchable text before detection runs. Handwritten content is handled through intelligent character recognition (ICR), which matters in contexts like medical records and legal documents where handwriting is common.
Every redaction is logged automatically: identifier category, document location, timestamp, and reviewer. The audit trail is available for compliance review.
Redactor also supports documents beyond PDFs, processing DOCX, XLSX, PPTX, and image files, covering the range of document types involved in compliance workflows across healthcare, legal, government, and research.
For organisations evaluating permanent redaction software for healthcare contexts, explore VIDIZMO Redactor's healthcare data redaction capabilities.
Conclusion
Overlay and permanent redaction look the same. They are not the same.
Overlay redaction hides data. Permanent redaction removes it. One satisfies compliance requirements. The other creates the appearance of compliance while leaving recoverable personal data in the file.
If you are not certain which type your current process produces, test it. The test takes two minutes. The gap it reveals could be the difference between compliant document sharing and an undiscovered breach.
Contact us see how VIDIZMO Redactor handles permanent redaction across documents, images, and scanned records.

About the Author

Jump to

How to Redact Cardholder Data from Call Recordings Stored in AWS S3
Best AI Redaction Software for Legal Teams in 2026
.jpg)

No Comments Yet
Let us know what you think