by Ali Rind, Last updated: May 14, 2026
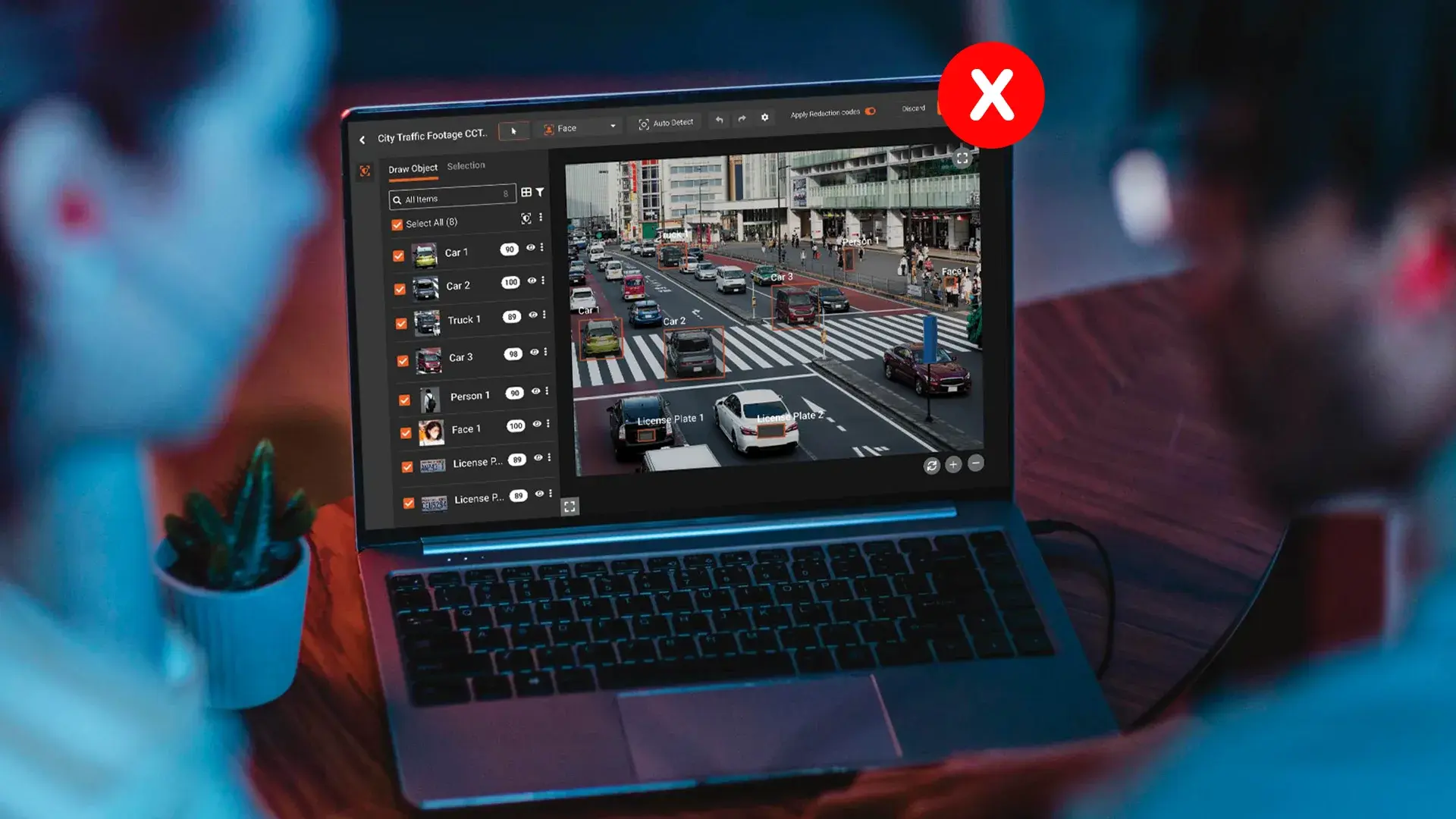
Redactions fail in seven predictable ways. The names on the failures change, but the underlying mistakes are the same handful of patterns repeated by teams who thought they had done the work correctly.
This post is a diagnostic guide. It walks through the seven mistakes that cause public redaction failures, explains where each one lives inside the file structure, and shows you how to catch it before release. If you want the case studies behind these mistakes, see our breakdown of five real redaction failures.
What is a redaction mistake?
A redaction mistake is any action that leaves redacted information recoverable after the file is released. The visible content looks correct. The underlying data does not.
These mistakes are not random. They cluster into seven recurring patterns, each tied to how digital files actually store information versus how they appear on screen.
1. Drawing a black box instead of removing the content
This is the redaction mistake everyone has heard of and a surprising number of teams still make. Someone draws a black rectangle, a white box, or a colored highlight over sensitive text in a PDF. The page looks redacted. The text layer is untouched.
This single pattern is behind most of the named public redaction failures of the last two decades. In each one, a reader selected the redacted area, copied it, and pasted the original text into a separate document.
How to catch it:
Open the redacted PDF in a fresh session. Click and drag to select the area behind each redaction, then paste into a plain text editor. If any original text appears, the redaction failed. The fix is a redaction tool that strips content out of the text stream rather than drawing over it, plus a flatten step before saving.
2. Leaving file metadata in place
You can redact every name on a page and still leak the patient's identity through the filename, the document properties, or the revision history. Author names, original filenames, comments, tracked changes, and EXIF data from embedded images often carry the same information that was redacted from the visible content.
A few examples of how this plays out: a healthcare file with "Smith_John_chart_v3.pdf" as the filename gives the patient away before anyone opens it. A legal filing's comments field can preserve an earlier unredacted draft in full. A scanned image's EXIF data can hand over the device, the location, and the exact timestamp.
How to catch it
After redacting, check the file's document properties (author, title, subject, comments) and confirm they are blank or replaced with generic values. PII redaction software that strips metadata as part of the standard workflow saves you from remembering to do it manually every time.
3. Forgetting PDF bookmarks, hyperlinks, and outline entries
PDFs store a separate layer of navigational structure that references content by name and location. Bookmarks, hyperlinks, outline entries, and the table of contents sit outside the main text layer and frequently survive a redaction that only touched the visible page.
The failure mode is straightforward. If a bookmark label says "Section 4: Pricing terms for Q3 2024" and the body of that section is redacted, the bookmark alone reveals what the redaction was meant to hide. The pattern has shown up in published government contracts.
How to catch it
Open the bookmarks panel in your PDF viewer and read every entry. If a label references redacted content, the redaction is incomplete. Strip or regenerate the document outline as part of the process, and flatten the file at the end.
4. Missing embedded objects and form fields
A document is not just the page you see. PDFs can carry attached files, JavaScript actions, and form fields with autofill values. Word documents can hold OLE objects, embedded spreadsheets, and linked images. Each one is a separate container, and a redaction pass that only touches the visible page leaves them alone.
The everyday version of this mistake: a PDF that carries the unredacted source document as an attachment, a Word file with a form field whose default value is the patient name you just redacted, or a scanned image with a thumbnail preview that was cached before redaction. Catching it means checking for attachments, form fields, embedded objects, and any content that is not directly part of the page rendering. A dedicated document redaction tool handles each of these layers in the same pass.
5. Relying on reversible blur or pixelation
Gaussian blur and pixelation are visual effects, not data removal. They make content harder to read with the naked eye, but the underlying pixel data is still in the file, and machine learning models can reconstruct blurred faces, license plates, and screen content well enough to recover names and numbers.
For faces in body-cam footage, license plates in surveillance video, and screens captured in screenshots, blur stopped being a defensible choice some time ago. Researchers have repeatedly shown that mosaic and Gaussian-blur redactions can be reversed with off-the-shelf tools.
How to catch it
For high-stakes visual redactions, use solid masking or full-pixel replacement. If you must use blur, confirm the implementation actually destroys the underlying pixel data rather than applying a filter on top.
6. Retaining context that allows reidentification
You can strip every direct identifier from a record (name, address, social security number) and still leave a file that traces back to one person. Dates, codes, locations, job titles, and rare medical conditions all work as indirect identifiers, and in small populations they are often enough on their own.
Consider a redacted medical record that reads "62-year-old female, rare autoimmune condition, employed at [redacted university], treated in March 2024." Every direct identifier is gone. The cohort is still small enough to identify the patient by elimination. The way to catch this is to read the redacted file as if you were trying to reidentify the subject. If you can narrow down to a small cohort from the surviving facts, the indirect identifiers need to come out too. This step matters most for healthcare, HR records, FOIA responses from small agencies, and any release where the source population is small enough for context to be revealing.
7. Skipping the verification step
The mistake that catches every other mistake on this list is releasing the file without testing it. A five-minute verification pass would have caught most of the public redaction failures of the last twenty years.
The shape of verification depends on the file. For PDFs and documents, run the copy-paste test on every redaction. For spreadsheets, unhide every sheet, row, and column in a fresh session. For video, scan the first and last frames of every tracked object and any frame where automated tracking reinitialized. For audio, walk through the transcript alongside the file and listen for late bleeps or surviving names. For all of them, check the metadata.
How to catch it
Make verification a required step, not an optional one. The teams that ship failed redactions are almost always the ones that trusted the tool and skipped the check.
How to verify a redaction by file type
Verification looks different for each file type. Most of the mistakes above slip through because teams use one verification approach across every format, which works for none of them. For teams handling PDFs at scale, verification has to be built into the batch process rather than applied one file at a time.
PDFs and Word documents
Open the file in a fresh session. Select the area behind each redaction, copy, and paste into a plain text editor. If any original text appears, the redaction failed. Then check document properties (author, title, subject, comments, revision history) and the bookmarks panel.
Spreadsheets
Open the file fresh. Right-click every sheet tab and unhide. Select all rows and unhide. Select all columns and unhide. Check named ranges and pivot table caches. If hidden data reappears, the redaction was hiding rather than deletion.
Images
Check EXIF metadata in any image properties viewer. Look for embedded thumbnails that may have been generated before redaction. For any masked region, confirm the masking is solid color rather than blur. If the file is a screenshot, scan scrollbars, taskbars, and unmasked corners for content that slipped through.
Video
Scan the first and last frame of every tracked redaction. Scan any frame where automated tracking reinitialized or where a tracked object briefly left and re-entered the frame. Check reflections in glass, mirrors, and screens. Confirm on-screen text (names on displays, license plates in the background) is masked across every frame.
Audio
Compare the audio against the source transcript. Listen for late bleeps where the redaction starts a fraction of a second after the name is spoken. Listen for early endings where the redaction stops before the speaker finishes the identifying phrase. For sensitive speaker identity, confirm voice modification was applied if voice prints could be used for identification.
A verification step that fits the file type catches mistakes that a generic "open and review" pass misses every time.
How AI redaction software prevents these mistakes
The seven mistakes above happen most often inside general-purpose tools that were never built for permanent content removal. PDF annotation tools, image editors, basic video editors, and spreadsheet software all let you draw over content. None of them treat redaction as a data operation.
VIDIZMO Redactor is built for that gap. Detection happens at the data level before anything is drawn on the page. Metadata is stripped as part of the standard workflow, not as a separate sanitization step. Bookmarks, hyperlinks, embedded objects, and form fields are handled in the same pass as the visible text.
Video tracking uses object detection to cover secondary subjects and reflections that manual tracking misses. Every redaction action is logged for a verification audit trail. The full feature set is documented on the AI-powered document redaction software product page.
For teams currently relying on general-purpose tools, the workflow change is what eliminates the mistakes.
Skip the seven mistakes entirely. Try VIDIZMO Redactor and get true content removal across PDFs, video, audio, and images in one workflow.

About the Author

Jump to

Redaction Mistakes: 5 Real Failures and How to Prevent Each One

How a PDF Redaction Tool Protects Sensitive Data Before Public Release
.webp)

No Comments Yet
Let us know what you think