by Ali Rind, Last updated: June 18, 2026

The data you train an AI on is regulated the same way as any other copy of that data. If it holds personal information, the laws that govern that information still apply once it goes into a training set, and one of them, the EU AI Act, now adds rules of its own for higher-risk systems. The practical effect is that "we are just using it to train a model" is not a category that sits outside privacy law. It sits squarely inside it.
This guide covers the three frameworks most teams have to answer to when training or customizing AI on their own data: GDPR, HIPAA, and the EU AI Act. For each, the questions that matter are when it applies and what it expects you to take out of the data. For the underlying reason any of this matters, that a model can memorize and later reveal what it was trained on, see removing PII from AI and ML training data.
Why privacy laws reach the data you train AI on
Personal data keeps its legal status when it moves into a training set. Using it for a new purpose does not strip the obligations that came with it.
Most personal data was collected for a specific reason: to serve a customer, treat a patient, process a transaction. Training a model on it is usually a different purpose from the one it was collected for, which is exactly the situation privacy law is built to govern. On top of that, a trained model can surface the data it learned, so the exposure is not theoretical. Two things follow. You need a lawful reason to use the data this way, and you need to limit what personal information goes into the set. Redaction is how teams handle the second part for everything that is not a clean spreadsheet.
GDPR: collect less, and redact what you keep
GDPR applies whenever the data describes people in the EU, no matter where your company is based. For training data, its most direct demand is data minimization.
Data minimization means you should hold only the personal data you actually need for the purpose at hand. Applied to a training set, the question becomes whether the model needs the identities or just the patterns, and for most models it is the patterns. A model learning to route tickets or flag unusual transactions does not need the customer's name to do it. Minimization points to taking those identifiers out before training rather than carrying them along.
Where personal data does need to stay, GDPR favors reducing its risk rather than leaving it exposed. Pseudonymization, replacing direct identifiers with stand-in values, is named in the regulation as a recognized safeguard, and redaction removes the identifiers outright. The difference between cutting data and substituting a masked value is worth understanding before you choose, and redaction compared with masking walks through when each fits. GDPR also expects privacy to be built into the design of a system from the start, which for a training pipeline means the cleanup is a planned stage, not a step you bolt on after a problem appears.
HIPAA: when training data counts as health data
HIPAA applies when the training data includes protected health information held by a healthcare provider, plan, or one of their business associates. If your set contains patient records, you have two clean options: train on data that has been de-identified, or have a legal basis such as patient authorization or a business associate agreement.
De-identification is the route most AI work takes, and HIPAA recognizes two ways to reach it. Safe Harbor removes eighteen categories of identifiers, including names, dates, record numbers, and contact details. Expert Determination has a qualified statistician certify that the re-identification risk is very small. The mechanics of both are covered in the researcher's guide to de-identifying sensitive data, and for the wider context of what HIPAA covers and why it matters for redaction, see what HIPAA is and how it applies.
The hard part for health data is the same as everywhere else: free text. A structured field labeled "patient name" is easy to remove. A clinical note that mentions the patient's spouse, employer, or home town hides identifiers inside ordinary sentences, and those are the ones that slip into a training set when only the structured columns get cleaned. Any narrative field in a health record needs detection that reads the language, not just a column filter.
The EU AI Act: a higher bar for high-risk systems
The EU AI Act is the first broad law written specifically for AI, and it adds obligations on top of GDPR rather than replacing them. Its training-data rules apply to systems it classifies as high-risk, a category that includes uses like hiring, credit scoring, education, biometric identification, and law enforcement.
For those systems, the Act requires documented data governance: you have to show how the training, validation, and test data was collected, prepared, cleaned, and checked for bias. This is worth being precise about, because it is easy to overstate. The Act is mainly concerned with data quality, representativeness, and bias rather than stripping out personal information, and it even allows sensitive data to be processed where that is strictly necessary to detect and correct bias. The redaction connection runs through the personal-data side: where a high-risk system is built on personal data, the Act leans on GDPR's tools, minimization, pseudonymization, access controls, to meet its governance duties. In practice that turns documented data cleanup from good hygiene into a legal expectation for these systems.
The timeline is in motion, so treat this as prepare-now rather than a fixed date. The high-risk obligations were originally set for August 2026, but an agreement reached in 2026 moves the main high-risk deadline toward December 2027, with systems embedded in regulated products getting longer still. The direction is settled even while the exact date is being finalized: high-risk AI built on people's data will have to show a governed, documented, minimized training pipeline.
What comes out across all three
The three frameworks ask different questions, but they converge on the same short list of what should leave a training set before it reaches a model:
- Direct identifiers: names, contact details, account and record numbers, government IDs.
- Health and biometric details, which carry the highest sensitivity under all three regimes.
- Identifiers buried in free text, notes, transcripts, and comments, where column-level cleaning never reaches them.
The throughline is also consistent. Bring in less personal data than you think you need, redact what has to stay, and keep a record of what was removed so you can show the work. The first is minimization, the second is redaction, and the third is the documentation every one of these laws expects.
How VIDIZMO Redactor supports a compliant training pipeline
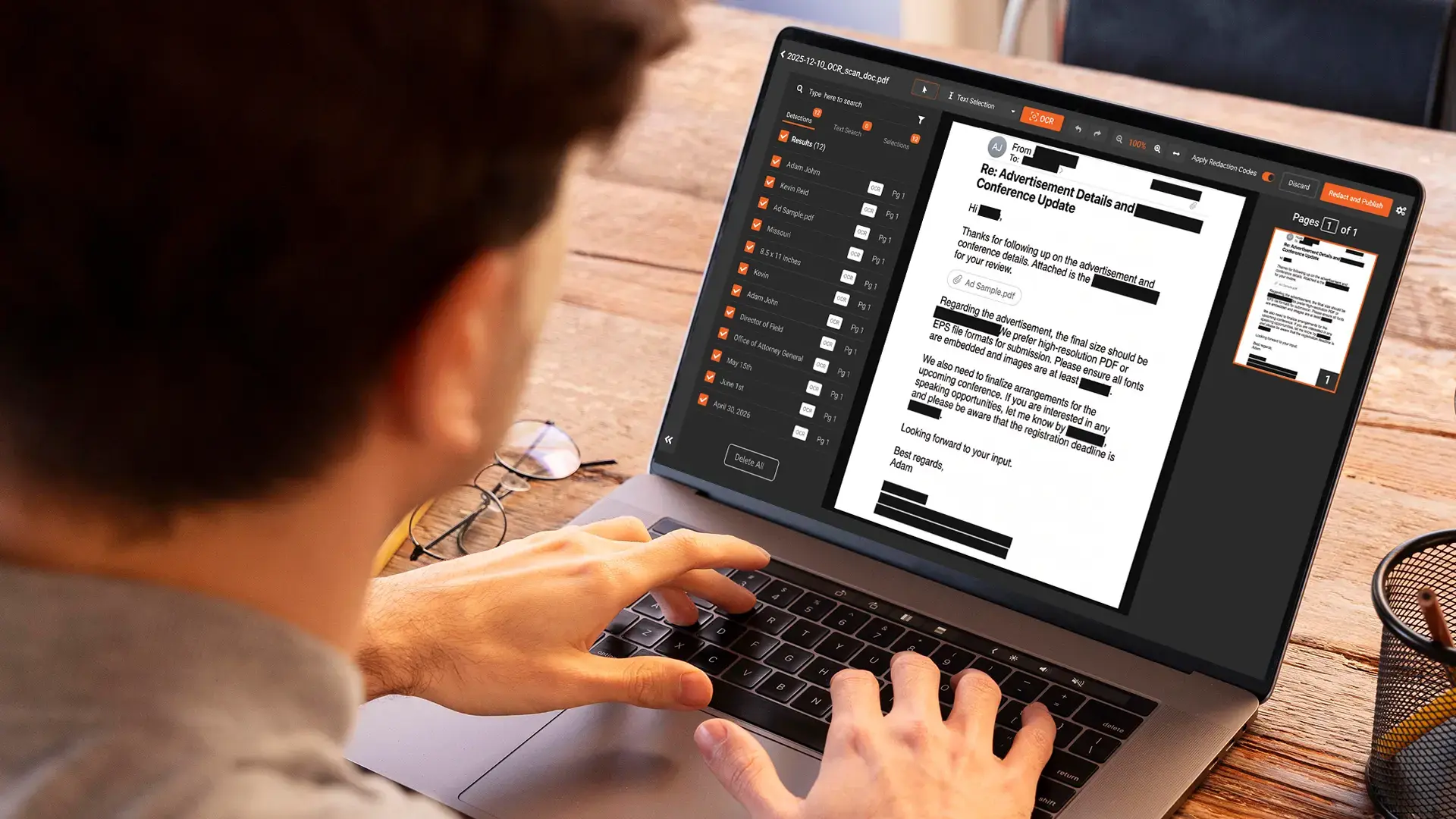
VIDIZMO Redactor prepares data for AI training in a way that holds up to a compliance review, across documents, images, audio, and video in one workflow. It detects dozens of categories of personal and sensitive information, reads identifiers inside free text rather than only structured fields, and handles scanned and image-based files through built-in text recognition so nothing is missed because it was locked in a picture.
Custom patterns catch the identifiers specific to your organization, and every redaction is logged, which gives you the documented record that GDPR, HIPAA, and the EU AI Act all expect. For the document side specifically, see AI-powered document redaction software.
Build a training set you can defend
VIDIZMO Redactor cleans personal and sensitive data out of your training sets at scale, with detection across documents, transcripts, recordings, and scanned files, and a full audit log of everything removed. If your team does not have the capacity to run it, managed redaction services can prepare the data for you. Start a free trial or talk to our team.

About the Author

Jump to
How to Redact Your Data Before Training or Customizing AI

How to Remove PII from AI and ML Training Data


No Comments Yet
Let us know what you think