by Ali Rind, Last updated: July 16, 2026

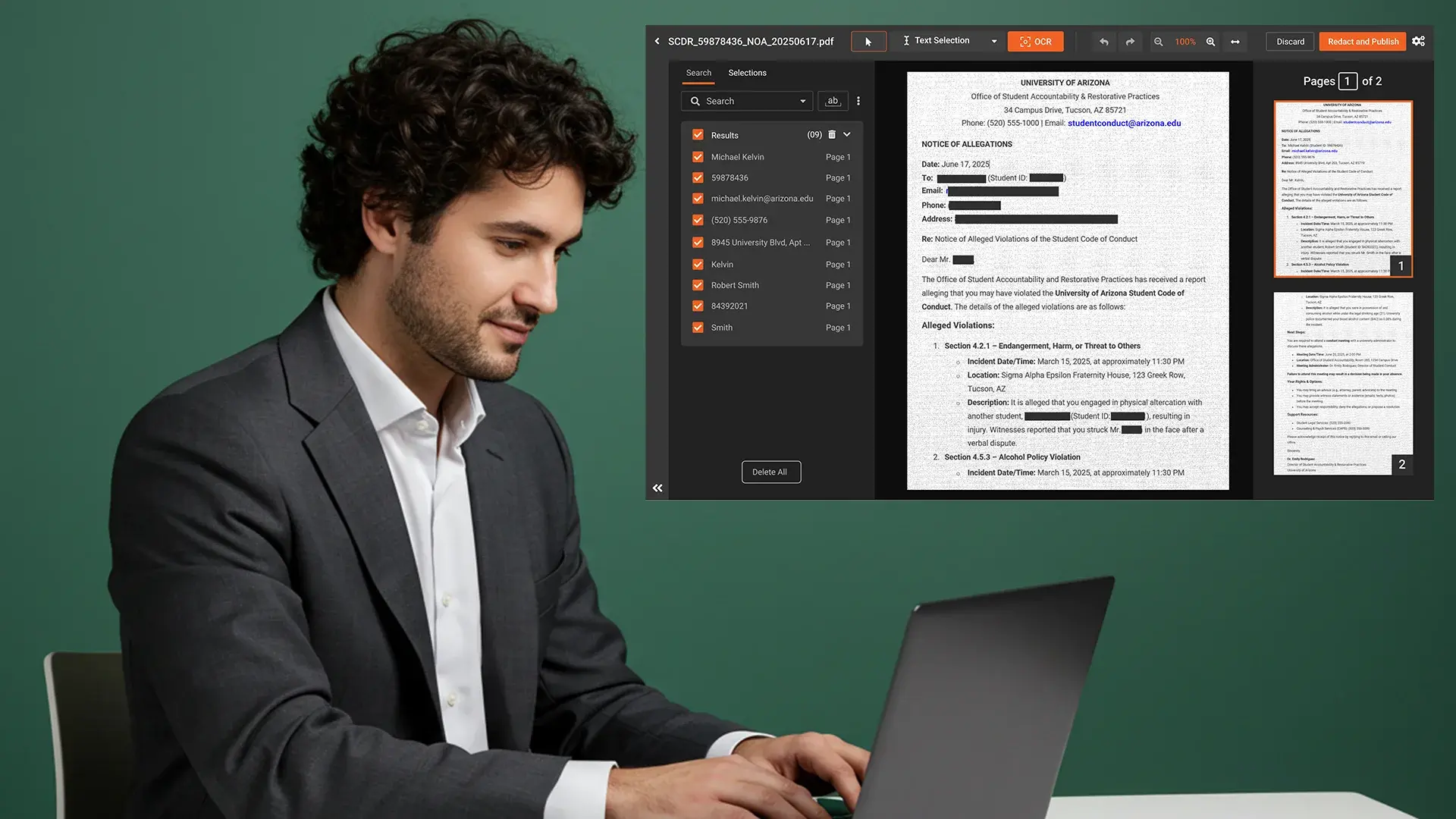
Healthcare organizations generate massive volumes of unstructured clinical text every day. Discharge summaries, radiology reports, physician notes, and pathology results all contain protected health information (PHI) buried within free-form narratives. Traditional redaction methods that rely on pattern matching struggle with this content because clinical language is inconsistent, abbreviated, and context-dependent.
Named Entity Recognition (NER) offers a fundamentally different approach. Instead of searching for rigid patterns, NER uses natural language processing to understand what words and phrases actually represent within a clinical context.
What Is Named Entity Recognition in Healthcare?
NER is a branch of natural language processing (NLP) that identifies and classifies specific entities within unstructured text. In healthcare, those entities include patient names, provider names, medication names, diagnoses, procedure codes, dates of service, facility names, and medical record numbers.
Where a pattern-based system looks for a specific format (like a nine-digit number for an SSN), NER analyzes the surrounding context to determine what a word or phrase represents. The word "Johnson" could be a patient name, a physician name, or a medical device brand. NER uses contextual clues, sentence structure, and domain-specific training to make that distinction correctly.
This matters because clinical documents do not follow a single template. A CT report from one hospital looks nothing like a discharge summary from another. Physician notes often include abbreviations, shorthand, and non-standard formatting that pattern-based tools miss entirely.
How NER Differs from Pattern-Based Redaction
Pattern-based redaction matches text against predefined rules. It works well for structured identifiers like Social Security numbers (XXX-XX-XXXX), phone numbers, or email addresses. These formats are predictable and consistent.
Clinical text is neither predictable nor consistent. Consider these challenges:
- Drug names vs. common words: "Celebrex" is a drug, but "aspirin" could appear in a discussion about treatment protocols or a patient's allergy list, each requiring different handling.
- Provider names: "Dr. Smith ordered the MRI" contains a provider name that needs redaction, but the pattern has no fixed format.
- Dates in clinical context: "The patient was seen three days after discharge" contains a relative date reference that pattern matching cannot resolve.
- Abbreviations: "Pt" (patient), "Dx" (diagnosis), and "Hx" (history) are standard in clinical notes but meaningless to generic pattern engines.
NER addresses these gaps by analyzing context rather than format. It identifies that "metformin 500mg BID" is a medication reference, "Dr. Patel" is a provider entity, and "Jefferson Memorial" is a facility name, all without needing a predefined list of every possible value.
Why NER Matters for HIPAA De-Identification
HIPAA's Safe Harbor method requires removal of 18 specific identifier categories from clinical data before it can be considered de-identified. Several of those categories, including names, geographic data smaller than a state, dates, and provider identifiers, appear as unstructured text in clinical records rather than in structured database fields.
For organizations working with:
- EHR free-text notes that contain embedded patient and provider names
- Radiology and pathology reports with facility identifiers, referring physician names, and dates
- Discharge summaries that reference other facilities, insurance information, and family member names
- Clinical trial documentation requiring PHI removal before sharing with sponsors or regulatory bodies
NER-powered redaction provides the contextual intelligence needed to locate these entities accurately. Pattern matching alone leaves gaps, particularly with names, provider references, and facility identifiers that have no predictable format.
To understand the full scope of what needs to be protected, see PHI Redaction in Healthcare Documents.
How AI-Powered Redaction Applies NER to Clinical Data
Modern AI redaction platforms combine NER with additional processing layers to handle the full complexity of clinical documents:
- Entity detection: NER models identify candidate entities (names, dates, medications, providers, facilities) within free text.
- Entity classification: Each detected entity is classified by type (patient name vs. provider name vs. medication) to determine whether it requires redaction.
- Confidence scoring: AI assigns confidence scores to each detection. Higher confidence detections can be auto-redacted, while lower confidence items get flagged for human review.
- Custom pattern layers: Regex-based patterns handle structured identifiers (SSNs, MRNs, phone numbers) that are better suited to format matching.
- Human-in-the-loop review: Reviewers verify AI detections before finalizing redaction, catching edge cases the model is uncertain about.
This layered approach, combining NER with pattern matching and human oversight, addresses the limitations of any single method used in isolation. Learn more about how this works in practice in How Healthcare Redaction Software Works.
Challenges Specific to Clinical NER
Clinical NER is harder than general-purpose NER for several reasons:
- Domain vocabulary: Medical terminology, abbreviations, and eponyms (e.g., "Hashimoto's thyroiditis") require domain-specific model training.
- Negation handling: "No evidence of malignancy" means something very different from "evidence of malignancy." NER must recognize negation patterns.
- Multi-word entities: "Cedars-Sinai Medical Center" is a single facility entity spanning four words.
- Co-reference resolution: "The patient" and "she" may refer to the same person across a document. Effective NER tracks these references.
Organizations evaluating redaction tools for clinical data should ask vendors how their NER models handle these clinical-specific challenges rather than assuming general-purpose models will perform adequately.
For a broader look at how AI redaction handles unstructured medical data, see How to Redact PHI in Medical Records for Clinical Research.
Key Takeaways
- NER identifies PHI in clinical text by analyzing context, not just matching patterns, making it essential for unstructured EHR notes and reports.
- Pattern-based redaction handles structured identifiers (SSNs, phone numbers) well but misses names, provider references, and facility identifiers.
- A layered approach combining NER, pattern matching, confidence scoring, and human review delivers the most reliable clinical PHI redaction.
- Clinical NER requires domain-specific model training to handle medical abbreviations, negation, and multi-word entities.
- Organizations should evaluate vendor NER capabilities specifically against clinical text, not just general-purpose benchmarks.
Choosing the Right Approach for Clinical Data De-Identification
Redacting PHI from unstructured clinical text is not a problem that pattern matching alone can solve. NER provides the contextual understanding needed to identify entities like patient names, provider references, and facility identifiers that appear in unpredictable formats across clinical documents.
The most effective approach combines NER with pattern-based detection, configurable confidence thresholds, and human review. VIDIZMO Redactor uses AI-powered detection that identifies 40+ PII and PHI types, including contextual NLP recognition for clinical entities, custom pattern support for organization-specific data, and configurable confidence thresholds that let organizations balance automation with human oversight.
Healthcare organizations dealing with hospital-wide workflows can also explore Redaction for Hospital Systems and Medical Record Redaction for Secure Data Sharing for guidance on scaling clinical redaction across departments and use cases.
Explore VIDIZMO Redactor's healthcare redaction capabilities.

People Also Ask
NER (Named Entity Recognition) in healthcare is an NLP technique that identifies and classifies specific entities like patient names, diagnoses, medications, provider names, and facility identifiers within unstructured clinical text.
Keyword-based detection searches for exact text matches against a list. NER analyzes context and sentence structure to determine what a word represents, making it far more effective for unstructured clinical documents where PHI appears in unpredictable formats.
Yes. Several HIPAA Safe Harbor identifier categories (names, dates, geographic data, provider identifiers) appear as unstructured text in clinical records. NER locates these entities based on context rather than format, improving de-identification accuracy.
Discharge summaries, radiology reports, pathology reports, physician notes, clinical trial case report forms, consultation notes, and any document containing free-text clinical narratives.
No. NER works best as part of a layered approach that also includes pattern-based detection for structured identifiers (SSNs, MRNs, phone numbers), confidence scoring, and human-in-the-loop review for uncertain detections.
NLP (Natural Language Processing) is the broader field of AI that processes human language. NER is a specific NLP task focused on identifying and classifying named entities within text. NER is one component of a larger NLP pipeline.
General-purpose NER models typically underperform on clinical text due to medical abbreviations, domain-specific vocabulary, and non-standard formatting. Models trained or fine-tuned on clinical data perform significantly better for healthcare use cases.
NER requires machine-readable text. For scanned documents, an OCR (Optical Character Recognition) step must convert the image to text first, and then NER can process the extracted text for entity detection. Learn more about OCR-based redaction and how it supports clinical document workflows.
About the Author

Jump to

PHI Redaction in Healthcare Training Videos

Redacting PHI from ABA Therapy Session Notes: A HIPAA Compliance

No Comments Yet
Let us know what you think