by Ali Rind, Last updated: July 16, 2026
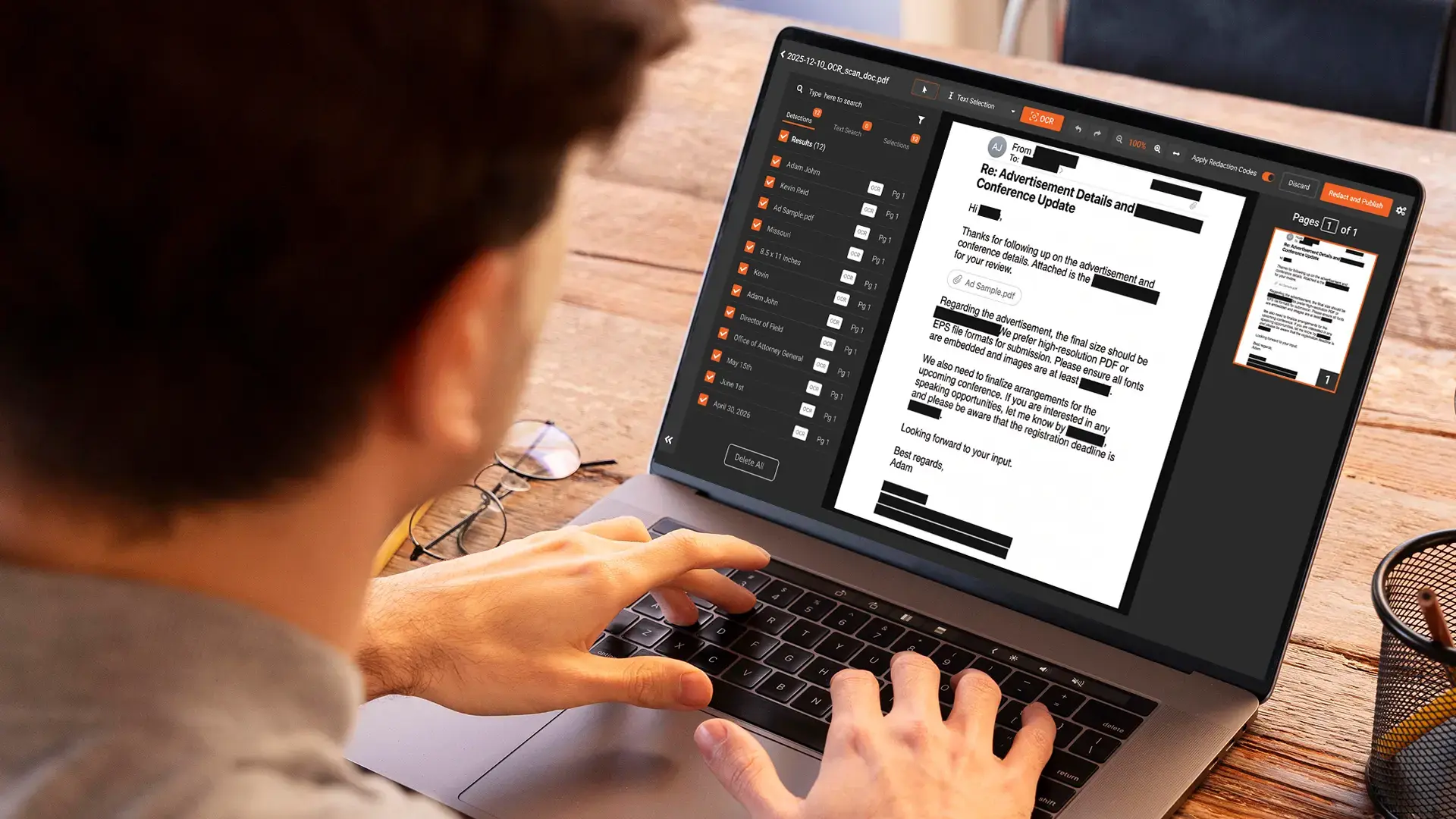
Using your own data to train or customize an AI is different from feeding a document into a chatbot. When you train, fine-tune, or connect your data to a model, that data becomes part of the system rather than a one-time input it reads and forgets. If the data carries customer names, account numbers, or health details, those identifiers can end up inside the model and come back out later. Redacting them first is the difference between a model built on safe data and one that carries a liability with every copy.
This guide is for teams putting their own data into AI: training a model, fine-tuning one, or connecting a knowledge base. It covers why redaction has to come first, what an AI can give away if you skip it, what to take out versus what the model actually needs, and a short checklist before you start. For the separate question of cleaning a single file before you paste it into a tool, see redacting medical records before uploading them to an AI tool. For the deeper technical view of how identifiers behave inside a trained model, see removing PII from AI and ML training data.
Why your data needs redacting before it trains an AI
The model keeps what you train it on, so anything sensitive in the data becomes part of what the model knows.
When a team uses an AI tool the normal way, they send it a prompt, it answers, and the exchange ends. Training is not that. Training and fine-tuning take a body of data and use it to adjust the model itself, which means the data shapes the model and, in some cases, gets stored in it. A name buried in a support ticket or an account number in a log is no longer sitting in a database you can lock down. It is part of a model that may be copied, shared with a vendor, or deployed to staff and customers.
That is why the cleanup has to happen before training, not after. Once a model has been trained on identifying data, taking that data back out usually means retraining from a cleaned set and replacing the old model everywhere it went. Redacting the data first is a one-time job. Leaving it in is a problem that travels with the model.
What an AI can give away later
A model can repeat the exact names, numbers, and details it was trained on, when someone prompts it the right way.
This is called memorization, and it is most likely for details the model saw more than once or for distinctive values like a full account number or a rare name. It does not happen with every model or every record, and it is not a certainty. But it happens often enough that anyone training on data with real identifiers in it should assume the risk is live.
The practical version: a model trained on unredacted customer records can, under the right prompt, surface a real customer's information to whoever is using it. The technical detail of how that extraction works is covered in the training data piece; for this guide, the point is that the data you train on can leave the model the same way it went in.
What to redact, and what the model still needs
Redact the identities, keep the signal. In most cases the model needs the patterns in your data, not the people in it.
A model that routes support tickets needs the wording of the problem and how it was resolved. It does not need the customer's name, email, or phone number to learn that. A model that flags unusual transactions needs the amount, timing, and type. It does not need the account holder's identity. The useful part of your data is almost always the behavior, the language, or the outcome, and the identifiers are passengers you can remove without hurting what the model learns.
Removing them is one of three choices. You can take the identifier out entirely, replace it with a generic label like "customer name," or swap in a realistic stand-in value. Which one fits depends on whether the model benefits from knowing a field was there at all. The difference between cutting data and masking it is worth understanding before you decide, and redaction compared with masking lays out when each is appropriate.
The hard part is free text. A spreadsheet column labeled "email" is easy to find and clean. A note that reads "spoke with the patient's wife, Sarah, about the test results" hides identifiers inside ordinary sentences, where simple find-and-replace cannot reach them. Catching those reliably takes detection tuned to read language and pick out names and references in context, which is the job named entity recognition does. Any free-text field is where identifiers most often slip through, so it deserves the closest look.
Training, fine-tuning, and connecting your data: what changes
There are three common ways companies put their own data into AI, and redaction matters in all three, for slightly different reasons.
Training and fine-tuning both fold your data into the model itself. Fine-tuning usually uses a smaller, more specific set, but the exposure is the same: whatever identifiers are in that set can be learned and later surfaced. The data has to be cleaned before the training run.
Connecting a knowledge base is the third way, and the one teams most often assume is safe. Here the model does not train on the data. Instead it reads from a separate store of your documents at the moment someone asks a question, and pulls relevant passages into its answer. The catch is that the model can quote those passages back word for word to whoever is asking. If a contract in that store names a client and lists their terms, the AI can read them aloud to anyone with access. So even when you are not training, the documents you connect to an AI need the same redaction pass before they go in.
In every case the rule is the same: clean the data before it reaches the model, whether the model learns it or only reads it.
A checklist before you start
Before any data goes into a model, run through these:
- List every source feeding the model, including logs, exports, attachments, and free-text notes, not just the obvious tables.
- Decide what the model actually needs to learn, and treat everything that is not signal as a candidate for removal.
- Find the identifiers in each source, paying special attention to free-text fields where they hide in ordinary sentences.
- Choose remove, mask, or substitute for each type of identifier, and apply it consistently across the whole set.
- Check the result on a sample before training, so you catch gaps while they are still cheap to fix.
- Keep a record of what was redacted, so you can show the data was cleaned if anyone asks.
How VIDIZMO Redactor prepares data for AI training
VIDIZMO Redactor cleans a body of data before it reaches a model, across documents, images, audio, and video in one workflow. It detects dozens of categories of personal and sensitive information, including custom patterns for the identifiers specific to your business, like internal account formats or project codes.
Scanned and image-based files are handled through built-in text recognition, so identifiers locked inside a picture of a page are caught rather than missed. Bulk processing runs across large sets rather than one file at a time, and every redaction is logged, so you have a record that the cleanup ran and what it covered. For the document side specifically, see AI-powered document redaction software.
Train on clean data, not a liability
VIDIZMO Redactor prepares your data for AI training and customization at scale, across documents, transcripts, recordings, and scanned files, with detection for your own custom identifiers and a full audit log of everything removed. If your team does not have the capacity to run the cleanup, managed redaction services can prepare the data for you. Start a free trial or talk to our team.

People Also Ask
Yes, if the data contains personal or sensitive information. A model can memorize identifiers in its training data and reproduce them later when prompted, so names, account numbers, and similar details should be removed before the training run. Redacting first is a one-time task, while removing data from an already-trained model means retraining from a cleaned set and replacing the old model wherever it was deployed.
Cleaning a file before you paste it into a tool protects a single exchange that ends when the answer comes back. Redacting data before training protects against the model keeping the data and surfacing it later, because training folds the data into the model itself. The first is a one-time precaution for one document; the second cleans an entire set before it becomes part of the model.
Usually not, because the identities are rarely what the model needs to learn. A model learns from the patterns, language, or outcomes in your data, and the personal identifiers are passengers that can be removed without affecting that. Accuracy drops only if you remove the signal itself rather than the identifiers, which is why the redaction should target names, numbers, and references rather than the substance the model is being trained on.
Yes. Even though the model does not train on a connected knowledge base, it reads from it at query time and can quote the contents back word for word to whoever is asking. Documents you connect to an AI should be redacted before they go in, the same way training data is, so the model cannot read sensitive passages aloud to anyone with access.
In free-text fields. Structured columns like "email" or "phone" are easy to find and clean, but notes, comments, and transcripts hide identifiers inside ordinary sentences where simple find-and-replace cannot reach them. Catching those reliably takes detection that reads language in context, and any free-text field should be treated as a likely gap until it has been checked.
About the Author

Jump to

How to Remove PII from AI and ML Training Data

What Privacy Laws Require You to Redact From AI Training Data

No Comments Yet
Let us know what you think